在《深入解析SQL Server并行执行原理及实践(上)》谈完并行执行的原理,咱们再来谈谈优化,到底并行执行能给我们带来哪些好处,我们又应该注意什么呢,下面展开。
Amdahl’s Law
再谈并行优化前我想有必要谈谈阿姆达尔定律,可惜老爷子去年已经驾鹤先去了。

其中 P:可以并行的百分比
N:算法并行计算使用的“CPU”
这里我们举个简单的例子,我们来做一份大餐,如图1-1所示:

图1-1
土豆泥,荷兰豆,鸡排还有整体组合各需十分钟。在这里前三个食材是可以共同执行的,也就是说4个步骤中3步可并行 P=3/4,其中3个食材可同时加工N=3,则根据公式S(N)=1/(1-0。75)+0。75/3 =2这个操作整体相比完全串行可提升200%即做这个大餐的时间由40分钟,缩短到20分钟。
这里实际引申出一个事实,整体的操作时间和整体事务中串行的比例多少有很大关联,这个引申到我们的并行调优中,并行可以改进查询,但受串行部分影响也是很大的,同时也告之我们没有必要过度串行优化,还是做大餐,即便并行可做的越来越多,但改进的效果却越发不明显,过度无谓的优化我们是应该避免的,如图1-2:
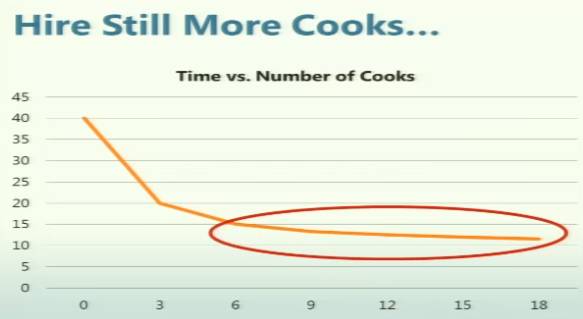
图1-2
SQL Server中禁止并行的一些操作
上面我们了解了并行的操作性,但在SQL Server并不是所有操作都可以并行的,有些操作符会导致整个执行计划无法并行,而有些会使得某些分支(branch)无法并行,下面罗列出相关的操作符对并行的影响,这些感兴趣的朋友可以自行测试。
执行计划禁止并行
T-SQL scalar functions
更新表变量数据
访问系统表
动态游标
Branche不能并型
TOP(global)
2012以前窗口函数(Row_Number)
Multi -Statement Function
Backward scan
CTE递归
并行执行的优点
说了一些限制,我们再来简单说下优点,要不开此文章的意义何在。实际上在上半部分文章中大家可能已经感受到它的优点了,这里再简单总结下。 实际上在并行中,计算工作是均匀的分配在参与并行的threads中,所有的threads同时工作,无先后之分。某些操作中threads自身的工作完成后还会协助threads工作,虽然会有短暂的CXPACKET等待(数据分布,预估等问题)但基本可以解决或是缓解。
执行时分支(Branchs)间有时可以是无顺序的,更好地增加了并行。
针对CPU-Bound的操作,SQL Server可以说时随着CPU(并行度)的增加,性能也基本是线性增加的。
并行相关的设置
SQL Server中有并行相关的一些设置,主要有两个:并行阈值及最大并行度。
并行阈值:上篇已经提到过,查询子树大小触发并行的条件,此值的设定仁者见仁智者见智了,一般设定为实例执行计划编译的平均查询子树大小上下幅度不超过20%
最大并行度:查询中的操作符可同时采用的线程数。这个值便随着NUMA的诞生应尤为注意,早在SQL 2005研发阶段,NUMA开始出现,而SQL 2005也提供了支持,但程度有限,随着SQLOS的进一步演化在SQL2008时对其支持已经很不错了,这里有大家都知道的NUMA架构下的foreign memory问题,实际上SQL Server在采用并行时会试图将并行的线程都集中在某个NUMA节点下,所以我们在配置初始参数时并行度最好控制在某个NUMA节点的核数内,而且最好是偶数,这里面涉及到很多SQLOS的知识,限于篇幅就不深入了。
使用并行应注意的问题
强制使用并行
Trace flag 8649 在SQL Server中可以不触发并行而手动指定并行,注意这个标记是无官方文档记录,勿轻易使用。使用时只需在查询最好加上query hint:Option(querytraceon 8649)即可。
数据分布不均,预估,碎片等问题
导致CXPACKET等待以及过多无谓IO,应对方式创建临时对象,更新统计信息,整理碎片等。
nested loop Join导致的随机IO,及nested loop join预读问题等
冷数据中使用并行nested join可能导致实例的IO稳定性受影响,面对具体场景应酌情使用。应对方式可以关闭nested loop预读,而nested loop预读时SQL Server也会试图将随机IO转化为连续IO,如具体应用合理应接受并行nested loop join。
线程饥饿问题(worker thread starvation)
前面我们说过,线程的授予是按照分支(branches)及并行度授予的,如果并行度高,此时复杂的查询下分支又很多,这个时候可能针对某个查询分配过多线程,加之这类查询又高并发,则这时出现线程饥饿的几率就大大增加了。具体生产中,这个应引起我们的注意。这里给大家举个简单的实例,感兴趣的同学可以自己测试下。这个查询有5个分支,分支所申请的线程就是5*16共80个!如图5-1:

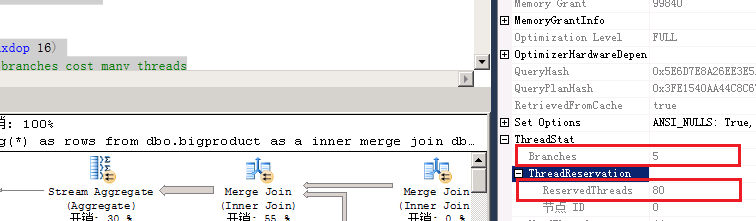
图5-1
并行死锁
并行执行提升查询响应时间,提高用户体验已经被我们所熟知了,但正如我一直强调的,任何事物均有利弊,我们要做的重点是权衡。并行死锁在并行执行中也会偶尔出现,官方给出的解释是SQL Server的“BUG”,你只需将查询的MAXDOP调整为1,死锁就会自动消失,但有时我们还应追溯其本质。这里用一个实例为大家说明下并行死锁的原因,以便我们更好的利用并行。
生成测试数据

接下来我们执行如下语句,取30000下最大偶数,此时我将执行并行数maxdop随意调整为奇数,3,5,7我的执行都可以迅速返回结果。

但当我将并行数调整为偶数时,执行时间居然长达数秒…打开trace profiler跟踪dead lock chain我们发现,当并行数为偶数时出现了死锁。
注:我们用Trace profiler捕捉死锁
如图6-1,6-2,6-3:

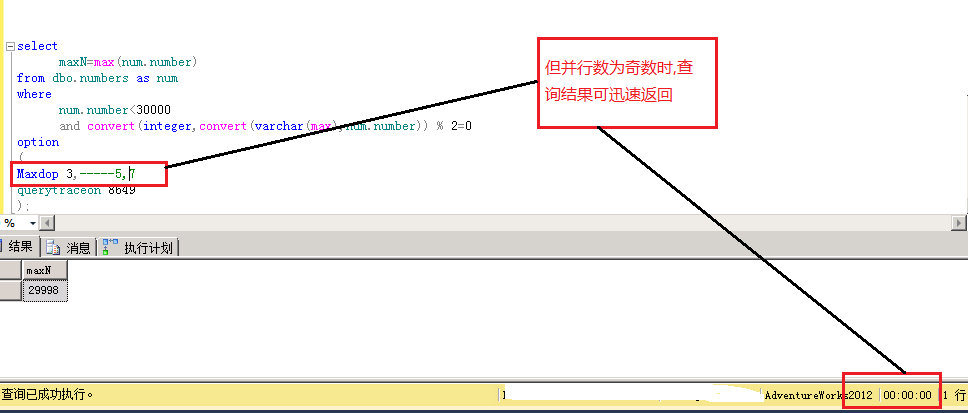
图6-1

图6-2

图6-3
有的同学可能觉得蹊跷,发生了什么我们具体分析下并行死锁的相应执行计划。
分析:
- 访问基表数据时用的是聚集索引扫描,但扫描方式是backward,而SQL server中只有forward scan可以并行扫描,backward只能串行扫描
- 因此在做exchange向各个threads分发数据时(distribute streams)采用roundrobin轮询分发数据,这势必造成奇偶数据按threads分开流向下一个过滤操作符
- 在Filter时将奇数的数据过滤,而相应的threads也就没有了数据
- 所以在最后exchange汇总数据时(gather streams)有的threads没有数据,因而造成死锁。
(注:thread 0为主线程,不参与并行分支工作)
分析如图6-4:
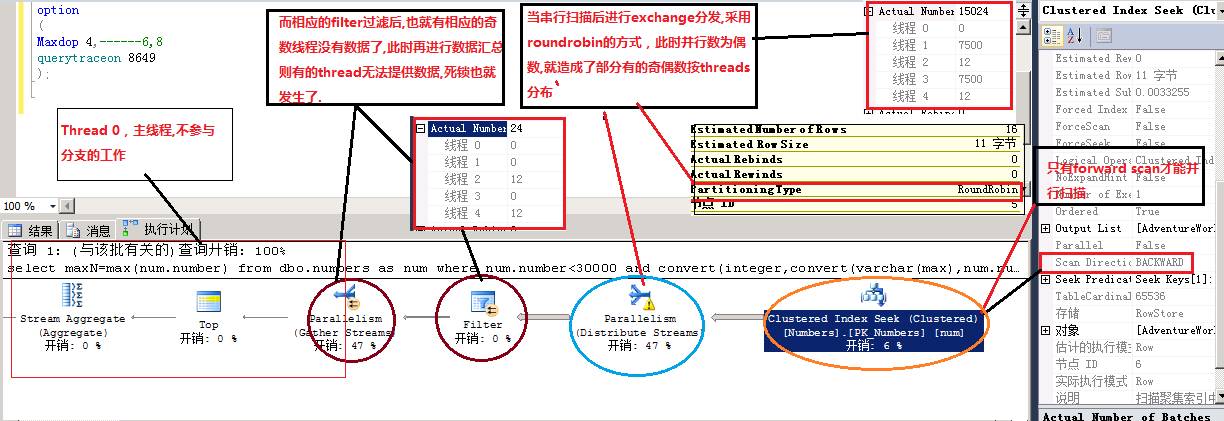
图6-4
而反观并行采用奇数并行数,这时当分发数据时就不会造成某个thread所持有的数据只是奇数或是偶数,也就不会造成后来的情形,死锁也就不会出现。如图6-4感兴趣的同学可以做实验调整并行数并阅读相应的执行计划。
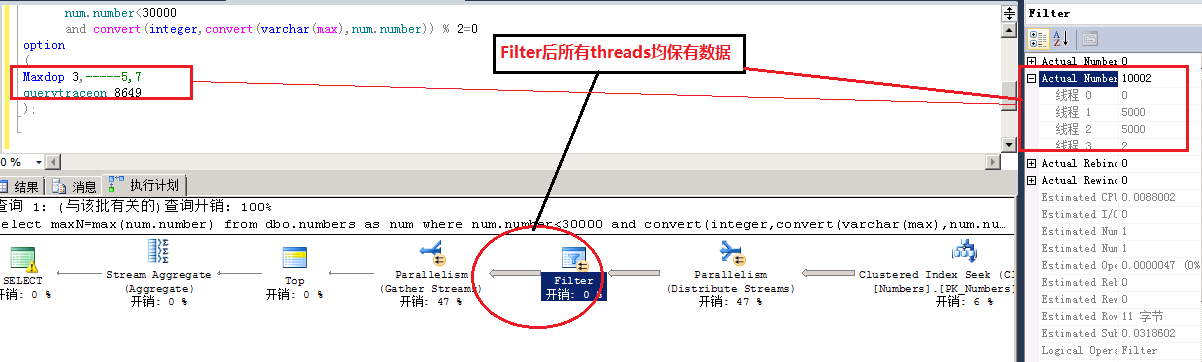
图6-5
至此我们应该可以明白了。
万事皆有因果,一个简单的BUG可以做为回应,但深究可能窥其本质,并且很有意思。技术人需有这种精神。
优化实践
最后咱们再通过一个简单的实例说下优化实践。
日常的OLTP环境中,有时会涉及到一些统计方面的SQL语句,这些语句可能消耗巨大,进而影响整体运行环境,这里我为大家介绍如何利用SQL Server中的“类MapReduce”方式,在特定的统计情形中不牺牲响应速度的情形下减少资源消耗。
我们可能经常会利用开窗函数对巨大的数据集进行分组统计排序。比如下面的例子:
脚本环境






当我们针对bigProduct表的productid分组,并按照bigTransactionHistory的actualcost及quantity分别排序取结果集语句如下:

执行此语句并输出实际执行计划如图7-1:
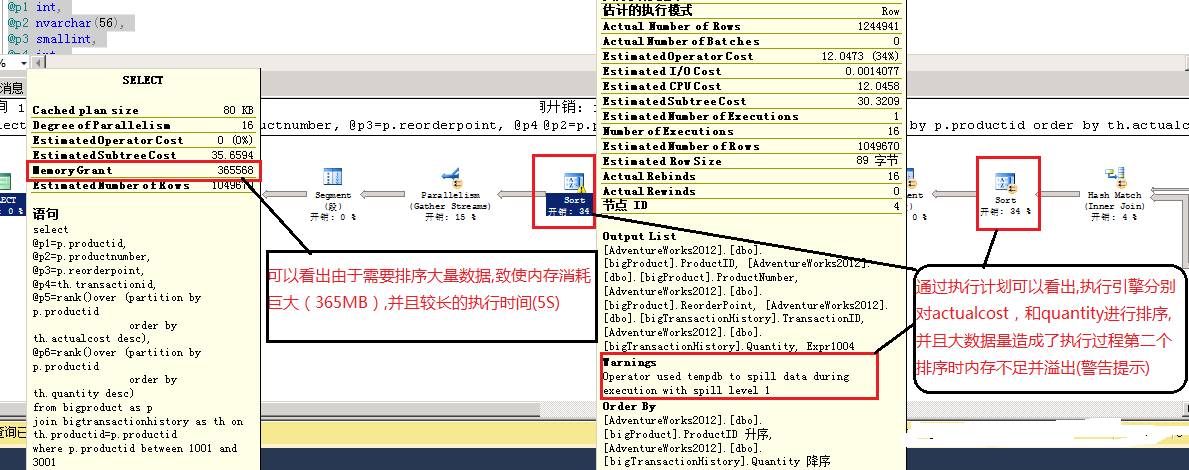
图7-1
可以看出我的这条语句由于对大量结果集进行排序,致使消耗了365MB的内存,并且由于分别对actualcost, quantity排序使得在进行第二个排序时内存不足并溢出,排序的操作只能在tempdb中进行。
Sort由于是典型的计算密集型运算符,此查询在我的机器上执行时间为5s。
大量的内存被个别查询长时间独占,使得Buffer Pool的稳定性下降,进而可能影响整体吞吐。
关于SQL Server的Sort限于篇幅这里就不细说了。
在介绍“类MapReduce”之前,我想先接着上面Sort溢出的现象给大家简单介绍下通过Query hints 来影响优化器的资源分配。

通过查询可以看出由于我加了Query Hint,改变了优化器的资源评估标准,使得优化器认为productid本身需要资源从1001 and 3001分配变为了1001 and 5001分配,内存申请由365MB变为了685MB,接近一倍的增长,避免了溢出。并且执行时间也由5S变为了2S,提升了用户体验。
如图7-2:
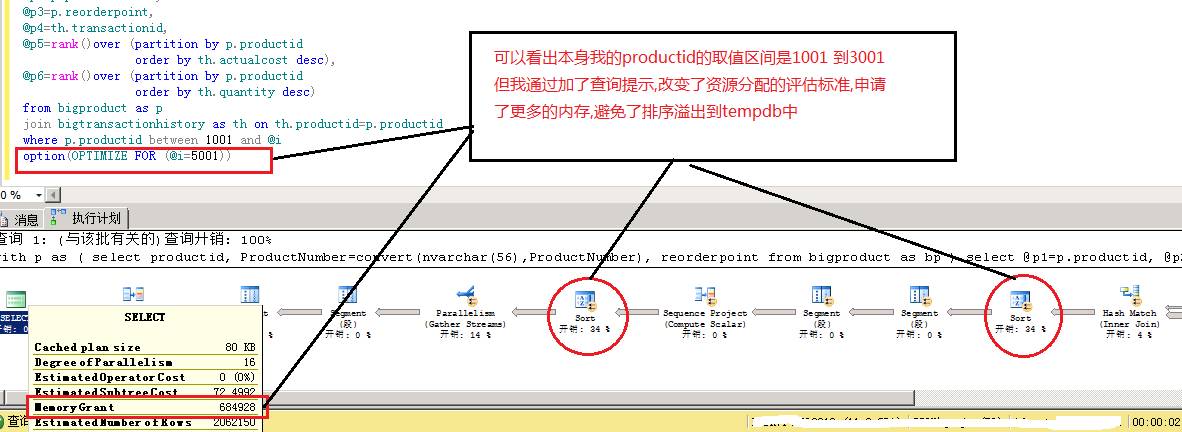
图7-2
可以看到溢出与不溢出在查询消耗时间上差别很大,但这样就是好了吗?其实未必,毕竟即便在非溢出的情形中将近700MB的内存近2s内被这个查询占用,这在高并发的OLTP环境中是伤全局的。那更理想的解决方式呢?
在并行执行计划中是多个线程(CPU核)协同工作,这里面的Sort面对大量数据结果集时即便多核同时进行,在复杂的预算面前也是有些力不从心。在分布式的思想中,讲究分而治之,我们只要将大的结果集化为多个小的部分并多核同时进行排序,这样就达到了分而治之的效果。也就是前面说的“MapReduce”。
幸好,在SQL Server实现并行运算的运算符”nestloop”与之相似。上篇中并行nested loop join的原理中已经提到。
并行Nest loop Join实现方式
在并行循环嵌套中,外表数据Scan,seek多线程(threads)同时进行(Map),而内表的在每个thread上串行执行(Reduce)。
优点:
- 可以减少执行过程中各线程数据流的数据交换
- 显著的减少内存需求
上述查询我用如下的方式实现:

执行中输出实际执行计划可以看出,此计划中消耗的内存15MB,和上述的执行计划相比有指数级的下降,同时执行时间为不到2s,保证执行时间的同时明显降低了资源消耗,从而避免了实例级的影响。
已经很美好了:)
如图7-3:
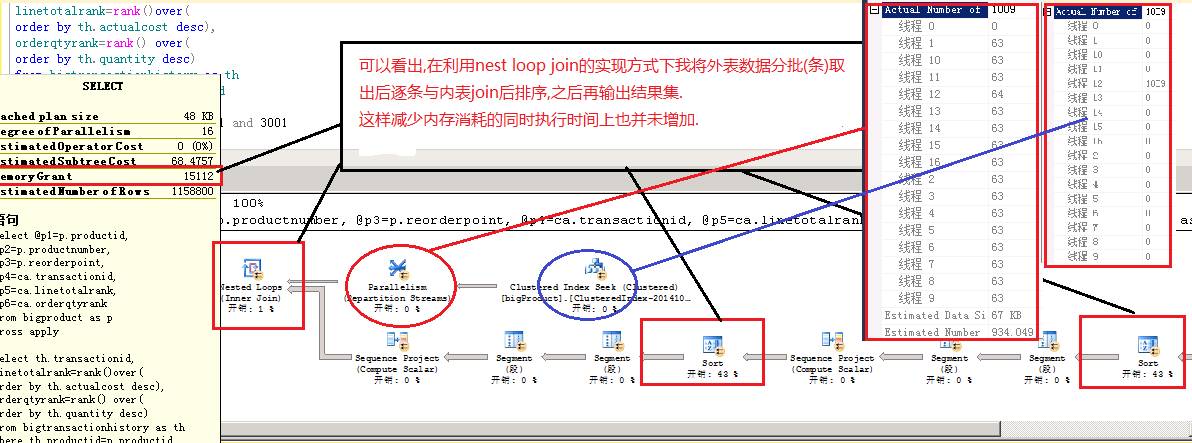
图7-3
到这里其实我们已经达到了我们想要的效果,但还可以更好吗?我们还需要多了解些。
上面我讲到了并行nest loops的优点,少资源占用,少数据交换。但就像在我以前的文章中说的那样:”任何术都是有缺陷的”,前文已经提到了并行中很可能造成数据的倾斜,如上图7-3中蓝线中标注的外表seek,实际是只在一个thread中完成的。优化器为我们加了数据交换,使得外部的数据在多个threads下分布均衡与内表匹配提升效率,但优化器可不会每次都如此“好心”(智能)。
其实在并行seek,scan中由于实现方式在05到08的过程变化很大(前文提到过),使得操作更需注意,这里我们直接上新的方案。

通过查询时输出执行计划 如图7-4所示。
我们可以看到通过将外表数据放入临时表中,使得内存消耗进一步降低,而数据较为平均的分布到多个threads中,你可能看到其中不少threads是没有数据的,其实有时需要我们根据查询管控并行度的。而在执行时间上有可能得到进一步的改善!
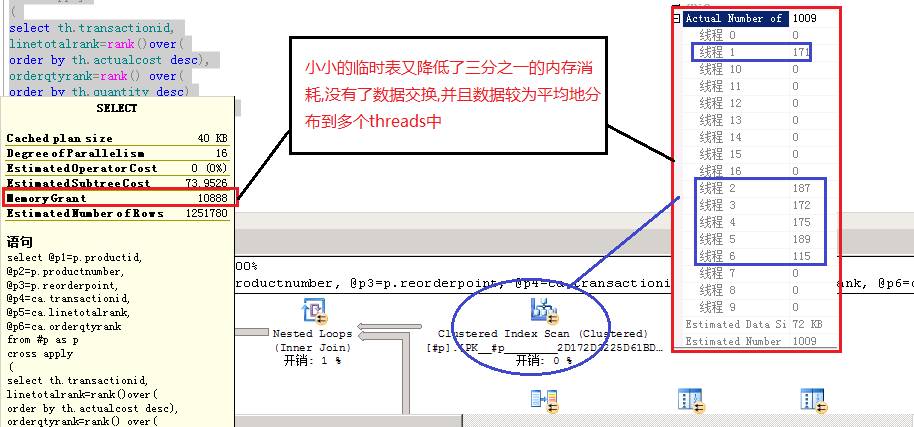
图7-4
至此,还有没有更好的方案呢,当然有,优化器就是让我们玩的!
我们可以通过临时表缓解数据分布不均的问题,但临时表创建导入也是成本啊,我们也可以用其他方式诱导优化器让数据分布彻底均匀,还记得前面说的Round Robin吗?这里我用特定的写法引导他的数据exchange.彻底平均分配,

如图7-5:
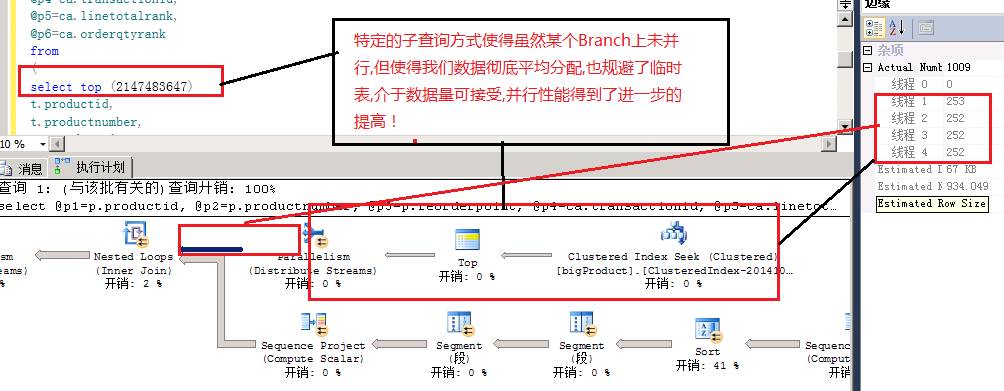
图7-5
至此这个优化更合理的解决了面临的问题!
我们的并行原理及实践也到此为止吧。
说点题外话,不少朋友认为SQL Server是小儿科,没内容,技术含量不高,而且在国内的互联网公司中又显得格格不入。这种想法真心Too Naive。这里我可以告诉大家,SQL Server,乃至关系型数据库的水很深。 如果你是相关的从业者,全身心地投入进来吧,其实很好玩。
