- 拟合是用一个连续函数(曲线)靠近给定的离散数据,使其与给定的数据相吻合。
- 数据拟合的算法相对比较简单,但调用不同工具和方法时的函数定义和参数设置有所差异,往往使小白感到困惑。
- 本文基于 Scipy 工具包,对单变量、多变量线性最小二乘拟合,指数函数、多项式函数、样条函数的非线性拟合,单变量、多变量的自定义函数拟合问题进行分析、给出完整例程和结果,数据拟合从此无忧。
1. 数据拟合
在科学研究和工程应用中经常通过测量、采样、实验等方法获得各种数据。对一组已知数据点集,通过调整拟合函数(曲线)的参数,使该函数与已知数据点集相吻合,这个过程称为数据拟合,又称曲线拟合。
插值和拟合都是根据一组已知数据点,求变化规律和特征相似的近似曲线的过程。但是插值要求近似曲线完全经过所有的给定数据点,而拟合只要求近似曲线在整体上尽可能接近数据点,并反映数据的变化规律和发展趋势。因此插值可以看作是一种特殊的拟合,是要求误差函数为 0 的拟合。
1.1 数据拟合问题的分类
数据拟合问题,可以从不同角度进行分类:
- 按照拟合函数分类,分为线性函数和非线性函数。非线性函数用于数据拟合,常用的有多项式函数、样条函数、指数函数和幂函数,针对具体问题还有自定义的特殊函数显示。
- 按照变量个数分类,分为单变量函数和多变量函数。
- 按照拟合模型分类,分为基于模型的数据拟合和无模型的函数拟合。基于模型的数据拟合,是通过建立数学模型描述输入输出变量之间的关系,拟合曲线不仅能拟合观测数据,拟合模型的参数通常具有明确的物理意义。而无模型的函数拟合,是指难以建立描述变量关系的数学模型,只能采用通用的函数和曲线拟合观测数据,例如多项式函数拟合、样条函数拟合,也包括机器学习和神经网络模型,这种模型的参数通常没有明确的意义。
1.2 数据拟合的原理和方法
数据拟合通过调整拟合函数中的待定参数,从整体上接近已知的数据点集。
这是一个优化问题,决策变量是拟合函数的待定参数,优化目标是观测数据与拟合函数的函数值之间的某种误差指标。典型的优化目标是拟合函数值与观测值的误差平方和;当观测数据的重要性不同或分布不均匀时,也可以使用加权误差平方和作为优化目标。
数据拟合的基本方法是最小二乘法。对于观测数据 ( x i , y i ) , i = 1 , . . n,将观测值 y i与拟合函数 y = f ( x , p ) 的计算值 f ( x i ) 的误差平方和最小作为优化问题的目标函数:


对于多变量线性最小二乘问题,设拟合函数为直线 f ( x ) = p 0 + p 1 ∗ x 1 + ⋯ + p m ∗ x m , 类似地,可以解出系数 p 0 , p 1 , ⋯ p m 。
对于非线性函数的拟合问题,通常也是按照最小二乘法的思路,求解上述误差平方和最小化这个非线性优化问题,常用的具体算法有搜索算法和迭代算法两类。
1.3 Python 数据拟合方法
数据拟合是常用算法,Python 语言的很多工具包都提供了数据拟合方法,常用的如 Scipy、Numpy、Statsmodel、Scikit-learn 工具包都带有数据拟合的函数与应用。
Scipy 是最常用的 Python 工具包,本系列中非线性规划、插值方法也都是使用 Scipy 工具包实现,因此仍以 Scipy 工具包讲解数据拟合问题。
Scipy 工具包对于不同类型的数据拟合问题,提供了不同的函数或类。由于 Scipy 工具包是多个团队合作完成,而且经过了不断更新,因此调用不同函数和方法时的函数定义和参数设置有所差异,往往使小白感到困惑。
本文对单变量、多变量线性最小二乘拟合,指数函数、多项式函数、样条函数的非线性拟合,单变量、多变量的自定义函数拟合问题进行分析、给出完整例程和结果,数据拟合从此无忧。
2. 线性最小二乘拟合
2.1 线性最小二乘拟合函数说明
线性最小二乘拟合是最简单和最常用的拟合方法。scipy.optimize 工具箱中的 leastsq()、lsq_linear(),scipy.stats 工具箱中的 linregress(),都可以实现线性最小二乘拟合。
2.1.1 scipy.optimize.leastsq 函数说明
leastsq() 根据观测数据进行最小二乘拟合计算,只需要观测值与拟合函数值的误差函数和待定参数 的初值,返回拟合函数中的待定参数 ( p 1 , ⋯ p m ) ,但不能提供参数估计的统计信息。leastsq() 可以进行单变量或多变量线性最小二乘拟合,对变量进行预处理后也可以进行多项式函数拟合。
scipy.optimize.leastsq(func, x0, args=(), Dfun=None, full_output=0, col_deriv=0, ftol=1.49012e-08, xtol=1.49012e-08, gtol=0.0, maxfev=0, epsfcn=None, factor=100, diag=None)
主要参数:
- func:可调用的函数,描述拟合函数的函数值与观测值的误差,形式为 error(p,x,y),具有一个或多个待定参数 p。误差函数的参数必须按照 (p,x,y) 的顺序排列,不能改变。
- x0:一维数组,待定参数 ( p 1 , ⋯ p m ) 的初值。
- args:元组,线性拟合时提供观测数据值 (xdata, ydata),观测数据 xdata 可以是一维数组(单变量问题),也可以是多维数组(多变量问题)。
返回值:
- x:一维数组,待定参数 ( p 1 , ⋯ p m )的最小二乘估计值。
2.1.2 scipy.stats.linregress 函数说明
linregress() 根据两组观测数据 (x,y) 进行线性最小二乘回归,不仅返回拟合函数中的待定参数 ( p 1 , p 1 ),而且可以提供参数估计的各种统计信息,但只能进行单变量线性拟合。
scipy.stats.linregress(x, y=None, alternative=‘two-sided’)
主要参数:
- x, y:x, y 是长度相同的一维数组。或者 x 是二维数组,且 y=none,则二维数组 x 相当于 长度相同的一维数组 x, y。
返回值:
- slope:斜率,直线 f ( x ) = p 0 + p 1 ∗ x中的 p 1。
- intercept:截距,直线 f ( x ) = p 0 + p 1 ∗ x中的 p 0 。
- rvalue:r^2 值,统计量。
- pvalue:p 值,P检验的统计量。
- stderr:标准差,统计量。
2.2 Python 例程:单变量线性拟合
程序说明:
- scipy.optimize.leastsq() 与 scipy.stats.linregress() 都可以进行单变量线性拟合。leastsq() 既可以用于单变量也可以用于多变量问题;linregress() 只能用于单变量问题,但可以给出很多参数估计的统计结果。
- leastsq() 要以子函数来定义观测值与拟合函数值的误差函数,例程中分别定义了拟合函数 fitfunc1(p, x) 与误差函数error1(p, x, y) ,是为了方便调用拟合函数计算拟合曲线在数据点的函数值。注意 p 为数组 。
- leastsq() 中误差函数的函数名可以任意定义,但误差函数的参数必须按照 (p,x,y) 的顺序排列,不能改变次序。
- leastsq() 中观测数据 (x, yObs) 是以动态参数 args 的方式进行传递的。这种处理方式非常独特,没有为什么, leastsq() 就是这样定义的。
- linregress() 只要将观测数据 (x,yObs) 作为参数,默认单变量线性拟合,不需要定义子函数。
- leastsq() 与 linregress() 进行线性拟合,得到的参数估计结果是相同的。
Python 例程:
# mathmodel25_v1.py# Demo25 of mathematical modeling algorithm# Demo of curve fitting with Scipy# Copyright 2021 YouCans, XUPT# Crated:2021-08-03# 1. 单变量线性拟合:最小二乘法 scipy.optimize.leastsqimport numpy as npimport matplotlib.pyplot as plt # 导入 Matplotlib 工具包from scipy.optimize import leastsq # 导入 scipy 中的最小二乘法拟合工具from scipy.stats import linregress # 导入 scipy 中的线性回归工具def fitfunc1(p, x): # 定义拟合函数为直线 p0, p1 = p # 拟合函数的参数 y = p0 + p1*x # 拟合函数的表达式 return ydef error1(p, x, y): # 定义观测值与拟合函数值的误差函数 err = fitfunc1(p,x) - y # 误差 return err# 创建给定数据点集 (x,yObs)p = [2.5, 1.5] # y = p[0] + p[1] * xx = np.array([0., 0.5, 1.5, 2.5, 4.5, 5.5, 7.5, 8.0, 8.5, 9.0, 10.0])y = p[0] + p[1] * x # 理论值 ynp.random.seed(1)yObs = y + np.random.randn(x.shape[-1]) # 生成带有噪声的观测数据# print(x.shape, y.shape, yObs.shape)# 由给定数据点集 (x,y) 求拟合函数的参数 pFitp0 = [1, 1] # 设置拟合函数的参数初值pFit, info = leastsq(error1, p0, args=(x,yObs)) # 最小二乘法求拟合参数print("Data fitting with Scipy.optimize.leastsq")print("y = p[0] + p[1] * x")print("p[0] = {:.4f}np[1] = {:.4f}".format(pFit[0], pFit[1]))# 由拟合函数 fitfunc 计算拟合曲线在数据点的函数值yFit = fitfunc1(pFit,x)# 比较:线性回归,可以返回斜率,截距,r 值,p 值,标准误差slope, intercept, r_value, p_value, std = linregress(x, yObs)print("nLinear regress with Scipy.stats.linregress")print("y = p[0] + p[1] * x")print("p[0] = {:.4f}".format(intercept)) # 输出截距 interceptprint("p[1] = {:.4f}".format(slope)) # 输出斜率 slopeprint("r^2_value: {:.4f}".format(r_value**2)) # 输出 r^2 值print("p_value: {:.4f}".format(p_value)) # 输出 p 值print("std: {:.4f}".format(std)) # 输出标准差 std# 绘图fig, ax = plt.subplots(figsize=(8,6))ax.text(8,3,"youcans-xupt",color='gainsboro')ax.set_title("Data fitting with linear least squares")plt.scatter(x, yObs, label="observed data")plt.plot(x, y, 'r--', label="theoretical curve")plt.plot(x, yFit, 'b-', label="fitting curve")plt.legend(loc="best")plt.show()程序运行结果:
Data fitting with Scipy.optimize.leastsqy = p[0] + p[1] * xp[0] = 2.2688p[1] = 1.5528Linear regress with Scipy.stats.linregressy = p[0] + p[1] * xp[0] = 2.2688p[1] = 1.5528r^2_value: 0.9521p_value: 0.0000std: 0.1161
程序说明:
- scipy.optimize.leastsq() 本质上是求解带有待定参数的误差函数最小化问题,因此可以用于多项式函数的最小二乘拟合,使用方法与线性拟合、指数拟合类似。
- 由于 leastsq() 要以子函数 error(p, x, y) 来定义观测值与拟合函数值的误差函数,在比较不同阶数的多项式函数拟合时需要定义多个对应的误差函数,比较繁琐。
- scipy.linalg.lstsq() 只要传入观测数据 (x,yObs),并将 x 按多项式阶数转换为 X,即可求出多项式函数的系数,不需要定义拟合函数或误差函数,非常适合比较不同阶数的多项式函数拟合的效果。
- 对于相同阶数的多项式函数,leastsq() 与 lstsq() 的参数估计和拟合结果是相同的。
- 增大多项式的阶数,可以减小拟合曲线与观测数据的误差平方和,但也更容易导致过拟合,虽然能更好地拟合训练数据,但并不能真实反映数据的总体规律,因而对于训练数据以外的测试数据的拟合效果反而降低了。
Python 例程:
# mathmodel25_v1.py# Demo25 of mathematical modeling algorithm# Demo of curve fitting with Scipy# Copyright 2021 YouCans, XUPT# Crated:2021-08-03# 4. 非线性函数拟合:多项式函数拟合(Polynomial function)import numpy as npimport matplotlib.pyplot as plt # 导入 Matplotlib 工具包from scipy.linalg import lstsq # 导入 scipy 中的 linalg, stats 函数库from scipy.optimize import leastsq # 导入 scipy 中的最小二乘法工具def fitfunc4(p, x): # 定义拟合函数 p0, p1, p2, p3 = p # 拟合函数的参数 y = p0 + p1*x + p2*x*x + p3*x*x*x # 拟合函数的表达式 return ydef error4(p, x, y): # 定义观测值与拟合函数值的误差函数 err = fitfunc4(p,x) - y # 残差 return err# 创建给定数据点集 (x,yObs)p = [1.0, 1.2, 0.5, 0.8] # y = p0 + ((x*x-p1)**2+p2) * np.sin(x*p3)func = lambda x: p[0]+((x*x-p[1])**2+p[2])*np.sin(x*p[3]) # 定义 y=f(x)x = np.linspace(-1, 2, 30)y = func(x) # 计算已知数据点的理论值 y =f(x)np.random.seed(1)yObs = y + 0.5*np.random.randn(x.shape[-1]) # 生成带有噪声的观测数据 yObs# 绘图fig, ax = plt.subplots(figsize=(8,6))ax.set_title("Polynomial fitting with least squares")plt.scatter(x, yObs, label="observed data")plt.plot(x, y, 'c--', label="theoretical curve")# 用 scipy.optimize.leastsq() 进行多项式函数拟合p0 = [1, 1, 1, 1] # 设置拟合函数的参数初值pFit, info = leastsq(error4, p0, args=(x,yObs)) # 最小二乘法求拟合参数yFit = fitfunc4(pFit, x) # 由拟合函数 fitfunc 计算拟合曲线在数据点的函数值ax.plot(x, yFit, '-', label='leastsq')print("Polynomial fitting by scipy.optimize.leastsq")print("y = p[0] + p[1]*x + p[2]*x^2 +p[3]*x^3") # 拟合函数的表达式print("p[0] = {:.4f}np[1] = {:.4f}np[2] = {:.4f}np[3] = {:.4f}".format(pFit[0], pFit[1], pFit[2], pFit[3]))# 用 scipy.linalg.lstsq() 进行多项式函数拟合print("nPolynomial fitting by scipy.linalg.lstsq")print("y = w[0] + w[1]*x + w[2]*x^2 + ... + w[m]*x^m") # 拟合函数的表达式# 最小二乘法多项式数据拟合,求解多项式函数的系数 W=[w[0],...w[m]]for order in range(1,5): # order = 3 # 多项式阶数, m X = np.array([[(xi ** i) for i in range(order + 1)] for xi in x]) Y = np.array(yObs).reshape((-1, 1)) W, res, rnk, s = lstsq(X, Y) # 最小二乘法求解 A*W = b print("order={:d}".format(order)) for i in range(order+1): # W = [w[0],...w[order]] print("tw[{:d}] = {:.4f}".format(i, W[i,0])) # 由拟合函数 fitfunc 计算拟合曲线在数据点的函数值 yFit = X.dot(W) # y = w[0] + w[1]*x + w[2]*x^2 + ... + w[m]*x^m # 绘图:n 次多项式函数拟合曲线 ax.plot(x, yFit, '-', label='order={}'.format(order))plt.legend(loc="best")plt.show()程序运行结果:
Polynomial fitting by scipy.optimize.leastsqy = p[0] + p[1]*x + p[2]*x^2 +p[3]*x^3p[0] = 0.9586p[1] = -0.4745p[2] = -0.3581p[3] = 1.1721Polynomial fitting by scipy.linalg.lstsqy = w[0] + w[1]*x + w[2]*x^2 + ... + w[m]*x^morder=1w[0] = 1.0331w[1] = 1.7354order=2w[0] = 0.2607w[1] = 0.3354w[2] = 1.4000order=3w[0] = 0.9586w[1] = -0.4745w[2] = -0.3581w[3] = 1.1721order=4w[0] = 1.0131w[1] = 1.6178w[2] = -1.1039w[3] = -1.5209w[4] = 1.3465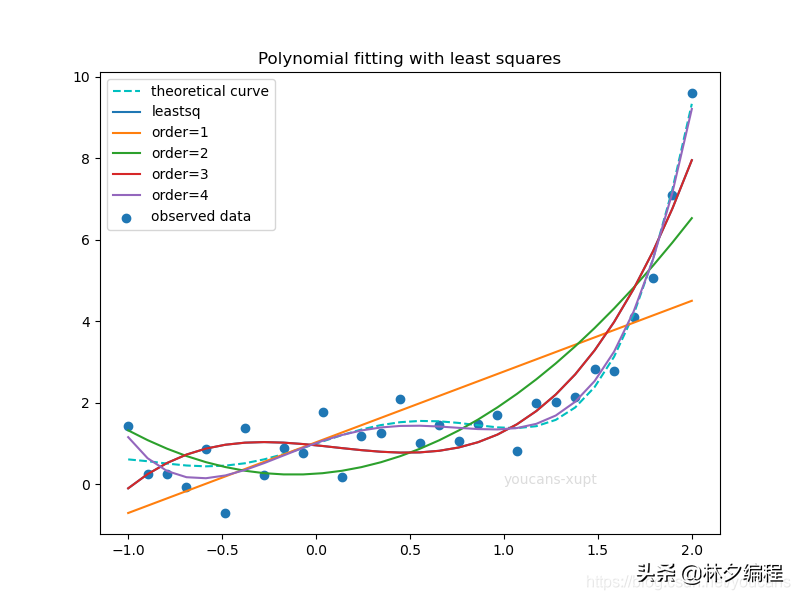
curve_fit() 使用非线性最小二乘法将自定义的拟合函数拟合到观测数据,不仅可以用于直线、二次曲线、三次曲线的拟合,而且可以适用于任意形式的自定义函数的拟合,使用非常方便。curve_fit() 允许进行单变量或多变量的自定义函数拟合。
**scipy.optimize.curve_fit(f,xdata,ydata,p0=None,sigma=None,absolute_sigma=False,check_finite=True,bounds=(-inf,inf),method=None,jac=None,kwargs) **
主要参数:
- f:可调用的函数,自定义的拟合函数,具有一个或多个待定参数。拟合函数的形式为 func(x,p1,p2,…),其中参数必须按照 (x,p1,p2,…) 的顺序排列,p1, p2,… 是标量不能表达为数组。
- xdata:n*m数组,n 为观测数据长度,m为变量个数。观测数据 xdata 可以是一维数组(单变量问题),也可以是多维数组(多变量问题)。
- ydata:数组,长度为观测数据长度 n。
- p0:可选项,待定参数 [p1,p2,…] 的初值,默认值无。
返回值:
- popt:待定参数 ( p 1 , ⋯ p m ) 的最小二乘估计值。
- pcov:参数 ( p 1 , ⋯ p m )的估计值 popt 的协方差,其对角线是各参数的方差。
4.2 Python 例程:单变量自定义函数曲线拟合
程序说明:
- 不同于 leastsq() 定义观测值与拟合函数值的误差函数,scipy.optimize.curve_fit() 直接定义一个自定义的拟合函数,更为直观和便于理解。
- curve_fit() 定义一个拟合函数,函数名可以任意定义,但拟合函数的参数必须按照 (x,p1,p2,…) 的顺序排列,不能改变次序。p1, p2,… 是标量,不能写成数组。注意 leastsq() 中误差函数的参数必须按照 (p,x,y) 的顺序排列,与 curve_fit() 不同。
- leastsq() 也可以对自定义的拟合函数进行最小二乘拟合。
- 由于本例程中自定义拟合函数使用了观测数据的实际模型,而不是通用的多项式函数或样条函数,因此拟合结果不仅能很好的拟合观测数据,而且能更准确地反映实际模型的趋势。
Python 例程:
# 6. 自定义函数曲线拟合:单变量import numpy as npimport matplotlib.pyplot as plt # 导入 Matplotlib 工具包from scipy.optimize import leastsq, curve_fit # 导入 scipy 中的曲线拟合工具def fitfunc6(x, p0, p1, p2, p3): # 定义拟合函数为自定义函数 # p0, p1, p2, p3 = p # 拟合函数的参数 y = p0 + ((x*x-p1)**2+ p2) * np.sin(x*p3) return y# def error6(p, x, y): # 定义观测值与拟合函数值的误差函数# p0, p1, p2, p3 = p# err = fitfunc6(x, p0, p1, p2, p3) - y # 计算残差# return err# 创建给定数据点集 (x, yObs)p0, p1, p2, p3 = [1.0, 1.2, 0.5, 0.8] # y = p0 + ((x*x-p1)**2+ p2) * np.sin(x*p3)x = np.linspace(-1, 2, 30)y = fitfunc6(x, p0, p1, p2, p3)np.random.seed(1)yObs = y + 0.5*np.random.randn(x.shape[-1]) # 生成带有噪声的观测数据# # 用 scipy.optimize.leastsq() 进行函数拟合# pIni = [1, 1, 1, 1] # 设置拟合函数的参数初值# pFit, info = leastsq(error6, pIni, args=(x, yObs)) # 最小二乘法求拟合参数# print("Data fitting of custom function by leastsq")# print("y = p0 + ((x*x-p1)**2+ p2) * np.sin(x*p3)")# print("p[0] = {:.4f}np[1] = {:.4f}np[2] = {:.4f}np[3] = {:.4f}"# .format(pFit[0], pFit[1], pFit[2], pFit[3]))# 用 scipy.optimize.curve_fit() 进行自定义函数拟合(单变量)pFit, pcov = curve_fit(fitfunc6, x, yObs)print("Data fitting of custom function by curve_fit:")print("y = p0 + ((x*x-p1)**2+ p2) * np.sin(x*p3)")print("p[0] = {:.4f}np[1] = {:.4f}np[2] = {:.4f}np[3] = {:.4f}" .format(pFit[0], pFit[1], pFit[2], pFit[3]))print("estimated covariancepcov:n",pcov)# 由拟合函数 fitfunc 计算拟合曲线在数据点的函数值yFit = fitfunc6(x, pFit[0], pFit[1], pFit[2], pFit[3])# 绘图fig, ax = plt.subplots(figsize=(8,6))ax.set_title("Data fitting of custom function")plt.scatter(x, yObs, label="observed data")plt.plot(x, y, 'r--', label="theoretical curve")plt.plot(x, yFit, 'b-', label="fitting curve")plt.legend(loc="best")plt.show()程序运行结果:
Data fitting of custom function by curve_fit:y = p0 + ((x*x-p1)**2+ p2) * np.sin(x*p3)p[0] = 0.9460p[1] = 1.1465p[2] = 0.8291p[3] = 0.6008estimated covariancepcov: [[ 0.01341654 0.00523061 -0.01645431 0.00455901] [ 0.00523061 0.02648836 -0.04442234 0.02821206] [-0.01645431 -0.04442234 0.20326672 -0.07482843] [ 0.00455901 0.02821206 -0.07482843 0.0388316 ]]结果分析:

4.3 Python 例程:多变量自定义函数曲线拟合
程序说明:
scipy.optimize.curve_fit() 既可以用于单变量也可以用于多变量问题,本例程求解一个二元非线性拟合问题。
curve_fit() 定义一个拟合函数 fitfunc7(X, p0, p1, p2, p3),函数名可以任意定义,但拟合函数的参数必须按照 (x,p1,p2,…) 的顺序排列,不能改变次序。p1, p2,… 是标量,不能写成数组。
curve_fit(fitfunc7, X, yObs) 中的 X 是 (n,m) 数组,n 是观测数据点集的长度,m 是变量个数。
Python 例程:
# mathmodel25_v1.py# Demo25 of mathematical modeling algorithm# Demo of curve fitting with Scipy# Copyright 2021 YouCans, XUPT# Crated:2021-08-03# 7. 自定义函数曲线拟合:多变量import numpy as npimport matplotlib.pyplot as plt # 导入 Matplotlib 工具包from scipy.optimize import curve_fit # 导入 scipy 中的曲线拟合工具def fitfunc7(X, p0, p1, p2, p3): # 定义多变量拟合函数, X 是向量 # p0, p1, p2, p3 = p # 拟合函数的参数 y = p0 + p1*X[0,:] + p2*X[1,:] + p3*np.sin(X[0,:]+X[1,:]+X[0,:]**2+X[1,:]**2) return y# 创建给定数据点集 (x,yObs)p = [1.0, 0.5, -0.5, 5.0] # 自定义函数的参数p0, p1, p2, p3 = p # y = p0 + p1*x1 + p2*x2 + p3*np.sin(x1+x2+x1^2+x2^2)np.random.seed(1)x1 = 2.0 * np.random.rand(8) # 生成随机数组,长度为 8x2 = 3.0 * np.random.rand(5) # 生成随机数组,取值范围 (0,3.0)xmesh1, xmesh2 = np.meshgrid(x1, x2) # 生成网格点的坐标 xx,yy (二维数组)xx1= xmesh1.reshape(xmesh1.shape[0]*xmesh1.shape[1], ) # 将网格点展平为一维数组xx2= xmesh2.reshape(xmesh2.shape[0]*xmesh2.shape[1], ) # 将网格点展平为一维数组X = np.vstack((xx1,xx2)) # 生成多变量数组,行数为变量个数y = fitfunc7(X, p0, p1, p2, p3) # 理论计算值 y=f(X,p)yObs = y + 0.2*np.random.randn(y.shape[-1]) # 生成带有噪声的观测数据print(x1.shape,x2.shape,xmesh1.shape,xx1.shape,X.shape)# 用 scipy.optimize.curve_fit() 进行自定义函数拟合(多变量)pFit, pcov = curve_fit(fitfunc7, X, yObs) # 非线性最小二乘法曲线拟合print("Data fitting of multivariable custom function")print("y = p0 + p1*x1 + p2*x2 + p3*np.sin(x1+x2+x1^2+x2^2)")for i in range(4): print("p[{:d}] = {:.4f}tp[{:d}]_fit = {:.4f}".format(i, p[i], i, pFit[i]))# 由拟合函数 fitfunc 计算拟合曲线在数据点的函数值yFit = fitfunc7(X, pFit[0], pFit[1], pFit[2], pFit[3])程序运行结果:
Data fitting of multivariable custom function:y = p0 + p1*x1 + p2*x2 + p3*np.sin(x1+x2+x1^2+x2^2)p[0] = 1.0000p[0]_fit = 1.1316p[1] = 0.5000p[1]_fit = 0.5020p[2] = -0.5000p[2]_fit = -0.5906p[3] = 5.0000p[3]_fit = 5.0061estimated covariancepcov: [[ 9.51937904e-03 -2.82863223e-03 -5.26393413e-03 -8.51457970e-04] [-2.82863223e-03 4.88275894e-03 9.39281331e-05 3.73832161e-04] [-5.26393413e-03 9.39281331e-05 3.86701646e-03 4.65766686e-04] [-8.51457970e-04 3.73832161e-04 4.65766686e-04 1.85374067e-03]]