背景
数据湖当前在国内外是比较热的方案,MarketsandMarkets市场调研显示预计数据湖市场规模在2024年会从2019年的79亿美金增长到201亿美金。一些企业已经构建了自己的云原生数据湖方案,有效解决了业务痛点;还有很多企业在构建或者计划构建自己的数据湖,Gartner 2020年发布的报告显示目前已经有39%的用户在使用数据湖,34%的用户考虑在1年内使用数据湖。随着对象存储等云原生存储技术的成熟,一开始大家会先把结构化、半结构化、图片、视频等数据存储在对象存储中。当需要对这些数据进行分析时,发现缺少面向分析的数据管理视图,在这样的背景下业界在面向云原生数据湖的元数据管理技术进行了广泛的探索和落地。
一、元数据管理面临的挑战
1、什么是数据湖
Wikipedia上说数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件,包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF、图像、音频、视频)。
从上面可以总结出数据湖具有以下特性:
- 数据来源:原始数据、转换数据
- 数据类型:结构化数据、半结构化数据、非结构化数据、二进制
- 数据湖存储:可扩展的海量数据存储服务
2、数据湖分析方案架构
当数据湖只是作为存储的时候架构架构比较清晰,在基于数据湖存储构建分析平台过程中,业界进行了大量的实践,基本的架构如下:
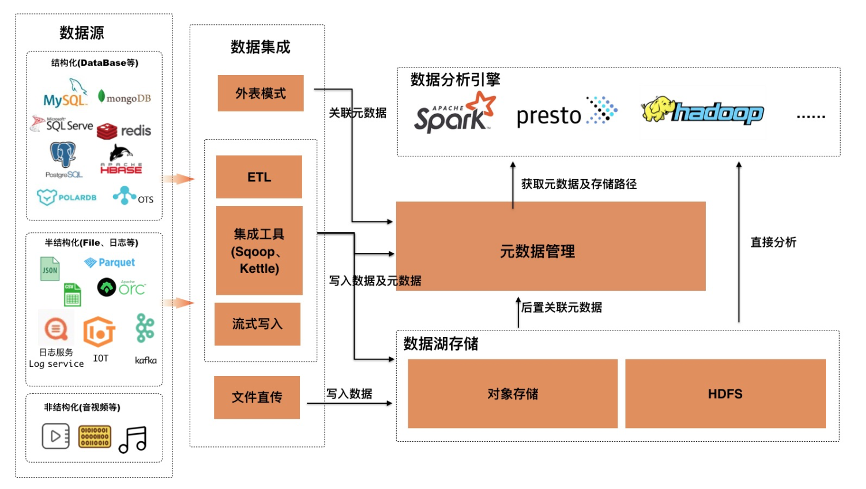

可以看出在对接多种数据源以及数据集成方式方面提供了友好的开放性,目前Apache Hudi原生对接了DLA Meta;在分析生态方面支持业界通用的数据模型标准(Hive Metastore);同时服务本身具备多租户、可扩展的能力满足企业级的需求。
三、元数据管理核心技术解析
下面主要介绍DLA Meta关于元数据多租户、元数据发现、海量分区管理三方面的技术实践,这几块也是目前业界核心关注和探索的问题。
1、元数据多租户管理
在大数据体系中,使用Hive MetaStore (下面简称HMS)作为元数据服务是非常普遍的使用方法。DLA 作为多租户的产品,其中一个比较重要的功能就是需要对不同用户的元数据进行隔离,而且需要拥有完整的权限体系;HMS 本身是不支持多租户和权限体系。阿里云DLA 重写了一套Meta 服务,其核心目标是兼容 HMS、支持多租户、支持完整的权限体系、同时支持存储各种数据源的元数据。
多租户实现
为了实现多租户功能,我们把每张库的元数据和阿里云的UID 进行关联,而表的元数据又是和库的元信息关联的。所以基于这种设计每张库、每张表都是可以对应到具体的用户。当用户请求元数据的时候,除了需要传进库名和表名,还需要将请求的阿里云UID 带进来,再结合上述关联关系就可以拿到相应用户的元数据。每个元数据的API 都有一个UID 参数,比如如果我们需要通过getTable 获取某个用户的表信息,整个流程如下:
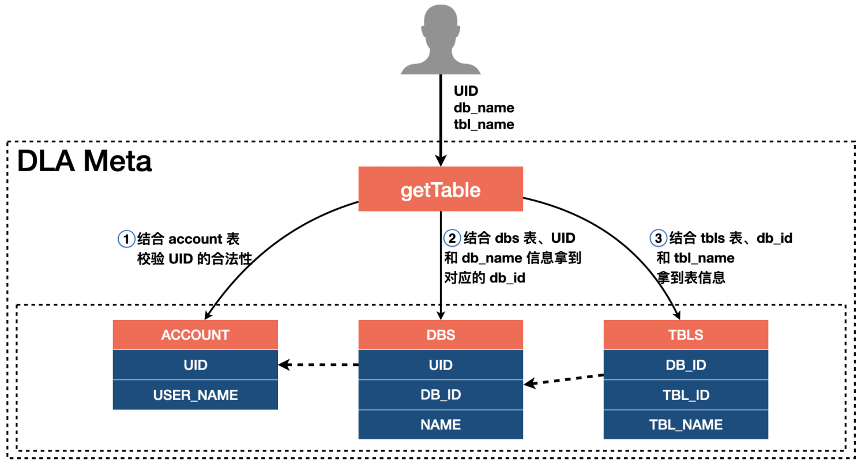
由于DLA Presto可以兼容MySQL 权限操作相关,为了降低用户的使用成本,当前DLA Meta 的权限是与MySQL 权限是兼容的,所以如果你对MySQL 的权限体系比较了解,那么这些知识是可以直接运用到DLA 的。
2、元数据发现Schema推断技术
元数据发现的定位:为OSS等存储上面的数据文件自动发现和构建表、字段、分区,并感知新增表&字段&分区等元数据信息,方便计算与分析。
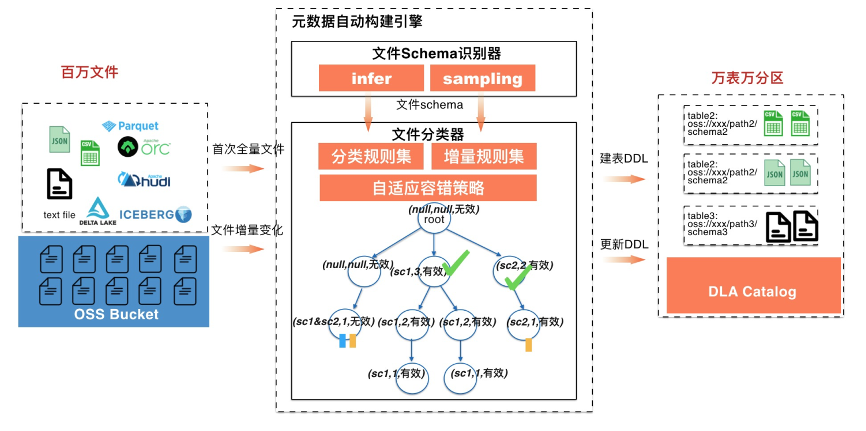
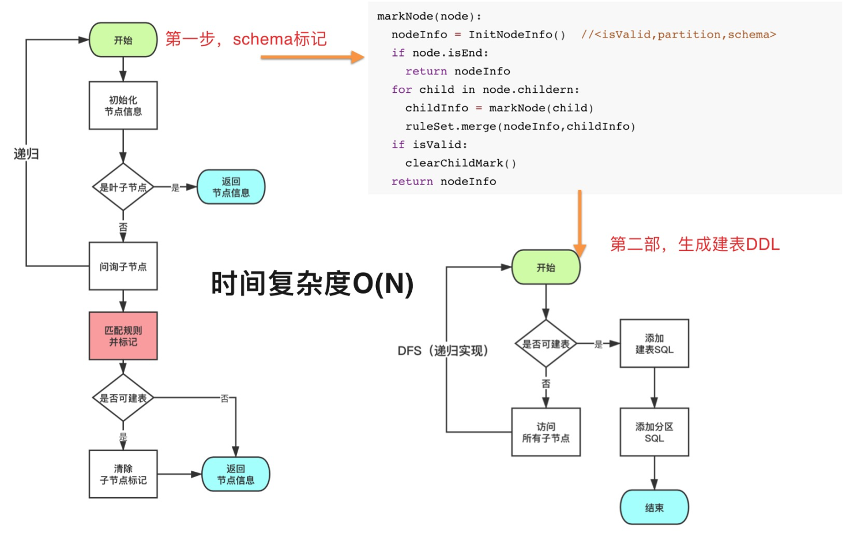
文件分类器:由于文件在OSS上面是按照目录存储的,当通过Schema识别器识别出了叶子节点目录下面的Schema情况后,如果每个叶子节点目录创建一张表,表会很多,管理复杂且难以分析。因此需要有一套文件分类器来聚合生成最终的表。且支持增量文件的Schema变更,比如添加字段、添加分区等。下面是整个分类算法过程,根据目录树形的结构,第一步先深度遍历并结合“文件Schema识别器”在每个节点聚合子节点的Schema是否兼容,如果兼容则把子目录向上合并为分区,如果不兼容则每个子目录创建一张表。经过第一步后每个节点是否可以创建表、分区信息,以及合并后的Schema都会存储在节点上面;第二步再次遍历可以生成对应的Meta创建事件。
3、海量分区处理技术
分区投影
在大数据场景中,分区是用于提升性能非常常见的方法,合理划分分区有利于计算引擎过滤掉大量无用的数据从而提升计算性能。但是如果分区非常多,比如单表数百万的分区,那么计算引擎从元数据服务查询分区所需要的时间就会上升,从而使得查询的整体时间变长。比如我们客户有张表有130多万分区,一个简单的分区过滤查询元数据访问这块就花了4秒以上的时间,而剩下的计算时间却不到1秒!
针对这个问题,我们设计开发出了一种叫做“分区映射”的功能,分区映射让用户指定分区的规则,然后具体每个SQL查询的分区会直接通过SQL语句中的查询条件结合用户创建表时候指定的规则直接在计算引擎中计算出来,从而不用去查询外部的元数据,避免元数据爆炸带来的性能问题。经测试,上述场景下,利用分区投影生成分区需要的时间降为1秒以下,大大提升查询效率。
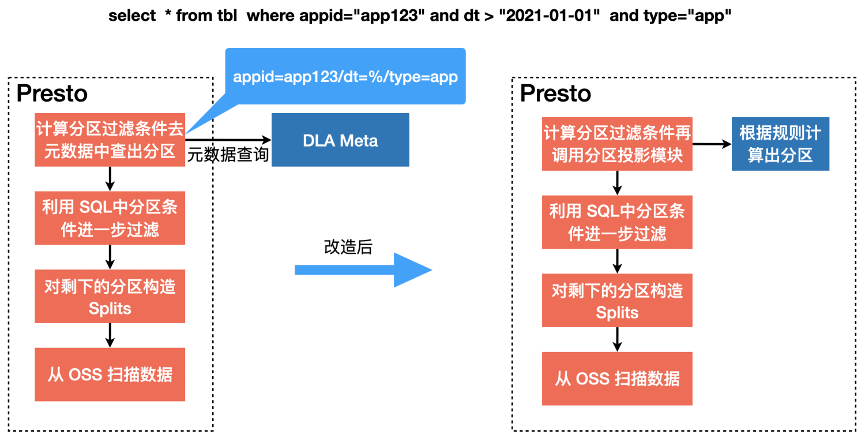
从上图可以看到DLA Meta中会存储库、表、分区的信息,使用当前方案OSS上面分区目录对应的分区信息会存储在DLA Meta服务中,当分析引擎访问这张表的时候,会通过DLA Meta服务读取大量的分区信息,这些分区信息会从底层的RDS中读出,这样会有一定的访问开销。如果使用到DLA Lakehouse方案,可以将大量的分区映射信息单独存储在基于OSS对象的Hudi Metatable中,Metatable底层基于HFile支持更新删除,通过KV存储方式提高分区查询效率。这样分析引擎在访问分区表的时候,可以只在Meta中读取库、表轻量的信息,分区信息可以通过读取OSS的对象获取。目前该方案还在规划中,DLA线上还不支持。
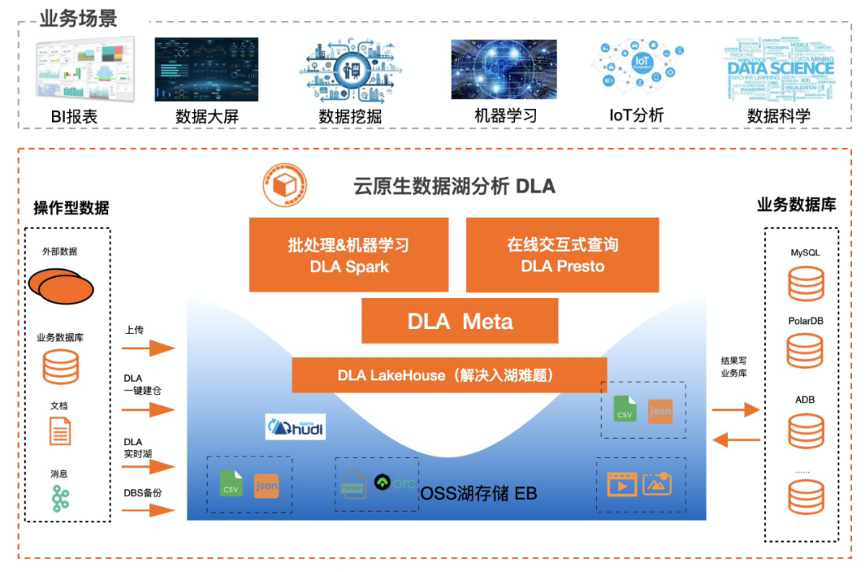
四、云原生数据湖最佳实践
最佳实践,以DLA为例子。DLA致力于帮助客户构建低成本、简单易用、弹性的数据平台,比传统Hadoop至少节约50%的成本。其中DLA Meta支持云上15+种数据数据源(OSS、HDFS、DB、DW)的统一视图,引入多租户、元数据发现,追求边际成本为0,免费提供使用。DLA Lakehouse基于Apache Hudi实现,主要目标是提供高效的湖仓,支持CDC及消息的增量写入,目前这块在加紧产品化中。DLA Serverless Presto是基于Apache PrestoDB研发的,主要是做联邦交互式查询与轻量级ETL。DLA支持Spark主要是为在湖上做大规模的ETL,并支持流计算、机器学习;比传统自建Spark有着300%的性价比提升,从ECS自建Spark或者Hive批处理迁移到DLA Spark可以节约50%的成本。基于DLA的一体化数据处理方案,可以支持BI报表、数据大屏、数据挖掘、机器学习、IOT分析、数据科学等多种业务场景。