目前promethues可以说是容器监控的标配,在k8s集群里面基本都会安装promethues。promethues结合grafana可以通过丰富的指标展现。下面通过一个压测的demo演示,容器底层对CPU和内存限制。
CPU
我们先介绍指标
# 容器CPU使用时间
rate(container_cpu_usage_seconds_total{pod=~"compute-.*", image!="", container!="POD"}[5m])
# 容器cpu request
avg(kube_pod_container_resource_requests_cpu_cores{pod=~"compute-.*"})
# 容器limit
avg(kube_pod_container_resource_limits_cpu_cores{pod=~"compute-.*"})
# 容器限流时间
rate(container_cpu_cfs_throttled_seconds_total{pod=~"compute-.*", container!="POD", image!=""}[5m])最开始,系统没有任何压力

cpu的占用(蓝色)0,限流(红色)0,request(绿色) 0.5核,limit(黄色) 0.7 核。然后我们开始加压。可以看到蓝色线打到 request 和limt 之间的 0.6 核。此时限流还是 0,没有触发红色限流。

当我们继续加压,请求超过limit的时候,CPU被控制在limit水位线。此时红色的限流开始增加。
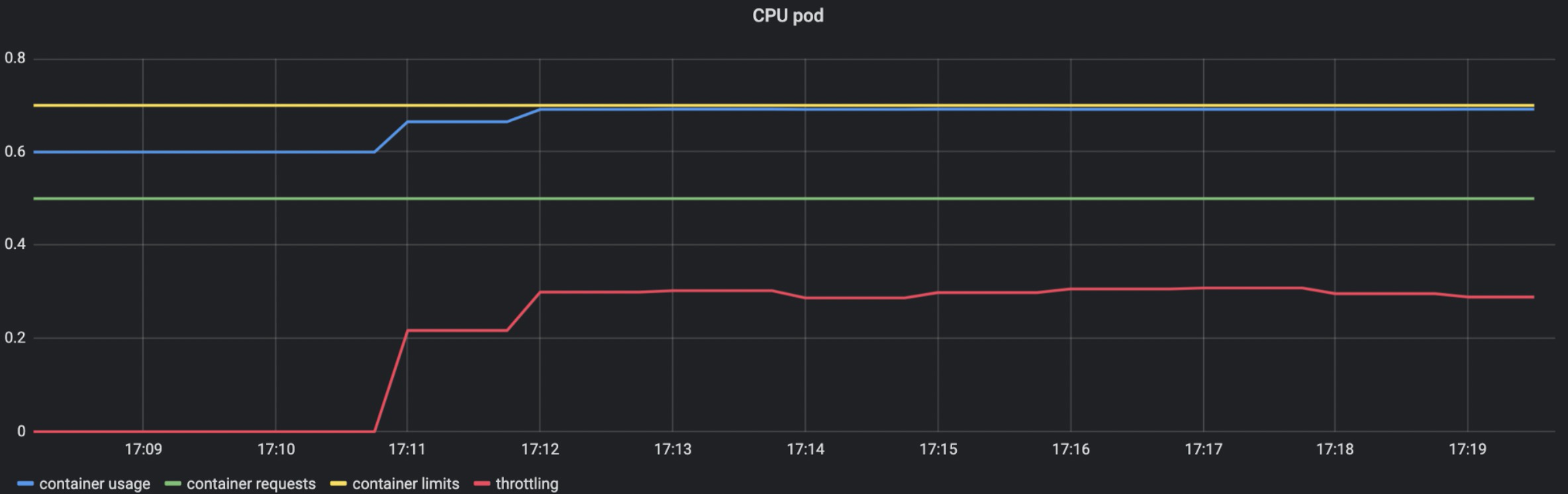
可以看到红色限流大概处于0.3核的位置,那么应用总的请求就是 0.3 + 0.7 ,只不过其中的0.3 被CPU限流了,实际只使用了 0.7 (limit)。当把应用负载降下来的时候,限流再次回到0。

内存
内存的限制就比较简单了,因为内存在底层是不可压缩的资源。同样的是我们先设置监控指标
# 内存用量
container_memory_working_set_bytes{pod_name=~"compute-.*", image!="", container!="POD"}
# 内存request
avg(kube_pod_container_resource_requests_memory_bytes{pod=~"compute-.*"})
# 内存limit
avg(kube_pod_container_resource_limits_memory_bytes{pod=~"compute-.*"})期初也是0压力,蓝色线为0.
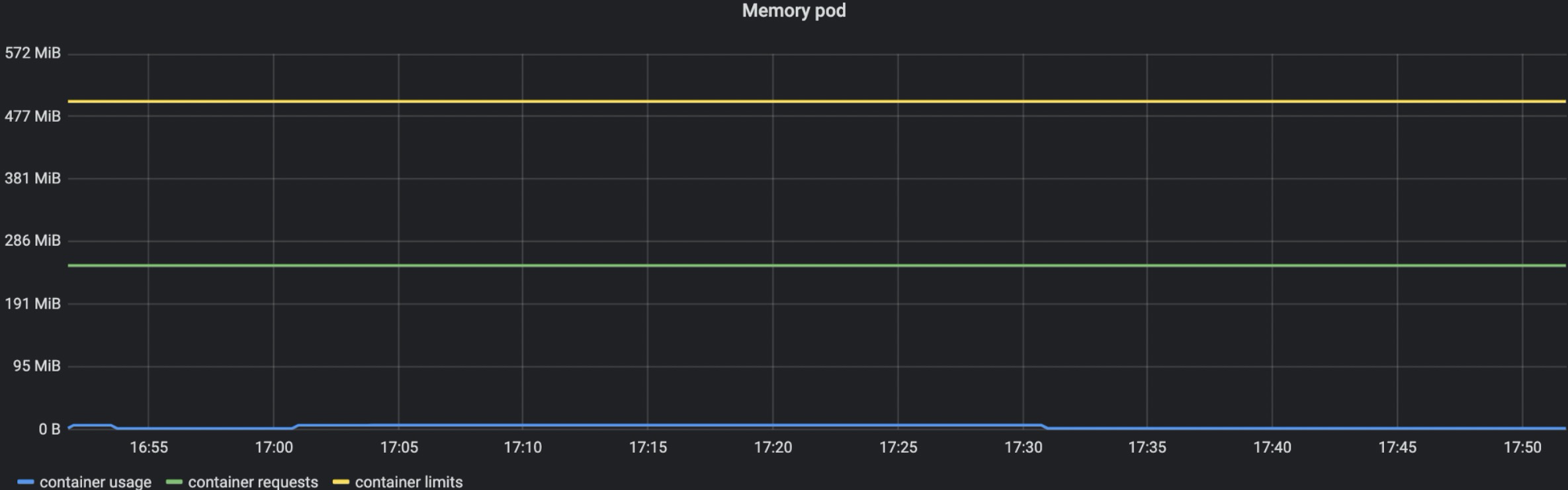
然后开始加压,申请内存,没有超过limit,正常运行

然后我们尝试超过limit,结果悲剧了

容器直接被干掉了,可以查看事件,发生了OOM。通过get event查看。
default 22s Warning OOMKilling node/aaa-resources-test-default-pool-6cad87bd-bgf4
Memory cgroup out of memory: Kill process 134119 (stress) score 1962 or sacrifice child
Killed process 134119 (stress) total-vm:519288kB, anon-rss:508260kB, file-rss:268kB, shmem-rss:0kB