前言
由于缓存的高并发和高性能已经在各种项目中被广泛使用,在读取缓存这方面基本都是一致的,大概都是按照下图的流程进行操作:
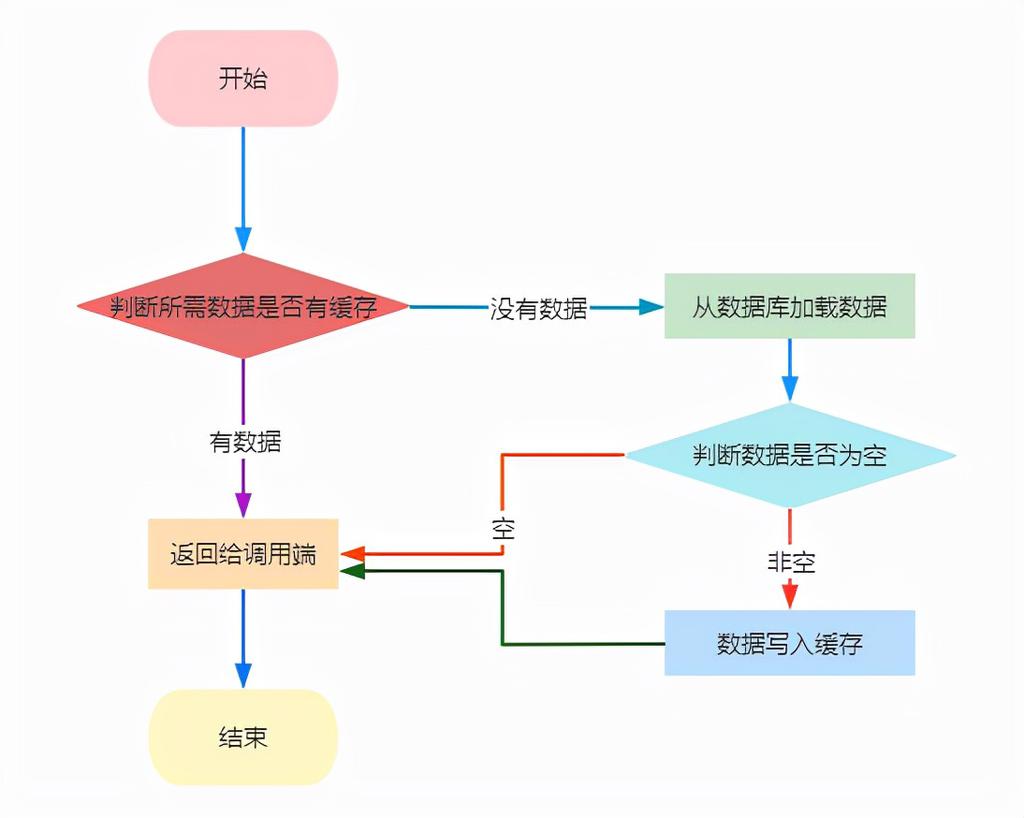

If an application updates information, it can follow the write-through strategy by making the modification to the data store, and by invalidating the corresponding item in the cache.
When the item is next required, using the cache-aside strategy will cause the updated data to be retrieved from the data store and added back into the cache.
这种方案会不会产生数据不一致的情况呢?比如下述这种情况:
有两个请求A和B,A进行查询同时B进行更新,假设发生下述情况:
①此时缓存刚好失效
②请求A 就会去查询数据库得到一个旧的值
③请求B将新的值写入数据库
④请求B写入成功后删除缓存
⑤请求A将查到的机制写入缓存,产生脏数据…
如果发声上述情况,确实会产生数据不一致的情况,但是XDM想一想,发生这种情况的概率是多少呢?如果先要产生这种结果,就必须有一个条件,就是请求B的操作时间非常短,短到什么程度呢,就是请求B写入数据库的操作要比请求A从数据库中读取数据的速度要快(因为redis非常快,因此操作redis的时间可以暂且忽略),只有这种情况下④才可能比⑤先发声,但是数据库的读操作要远比写操作快的多,不然做读写分离干嘛呢?所以这种情况发生的概率是非常非常非常的低,但是如果强迫症患者出现必须要解决怎么办呢?就可以采用给缓存设置过期时间或者采用第二种方案的延时双删策略,保证读请求完成之后在进行删除操作。
最后的问题
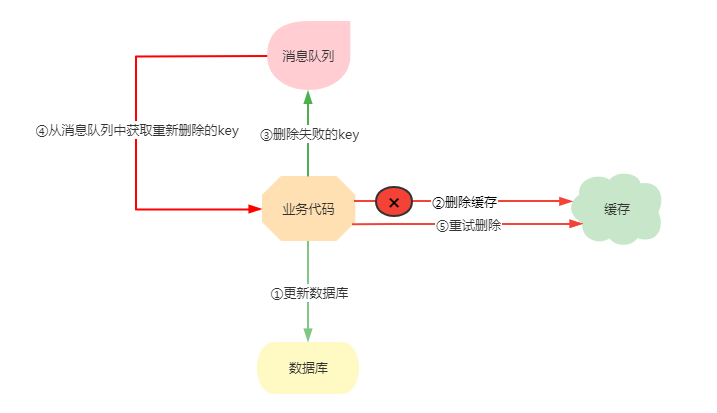
还有问题呀,就是最终解决方案三可能 出现的极低概率的数据不一致的方案是采用方案二的延时双删策略,可是在方案二中也说了,如果出现缓存删除失败的情况咋办?那不是还会出现数据不一致的问题吗?这个问题到底如何解决呢?这里提供一个重试机制,删除失败就重试一次呗,这里提供一种重试的方案。
①更新数据库
②由于各种原因缓存删除失败
③将删除失败的缓存放入消息队列中
④业务代码从消息队列中获取需要删除的key
⑤继续尝试删除操作,直到成功