导言
大多数与图像识别相关的分类问题都存在着众所周知的/既定的问题。例如,通常情况下,没有足够的数据来对分类系统进行适当的训练,这些数据涵盖的类可能会有所不足,而且最常见的情况是,使用未经仔细检查的数据将意味着我们对数据的标签缺乏合理的分类。


通过存储从模型预测中获取的真阳性、假阳性、真阴性和假阴性的每个标签的个数,我们可以使用查全率和精确性来估计每个标签的性能。精度的定义是:
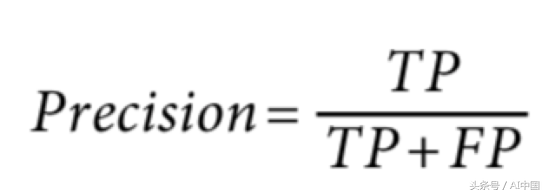
查全率/精确性会暴露出分类不平衡的问题,但并不能解决它。但是,有一些方法可以缓解分类不平衡的问题:
通过给每个标签分配不同的系数;
通过对原始数据集进行重新采样,或者对少数类进行过采样或对多数类进行过采样。也就是说,由于分类边界的更”严格”,数据集太小容易带来误差,让过采样更容易导致过度拟合。
通过应用SMOTE方法(对少数过采样进行合成的技术)来解决频繁对分类数据进行复制的问题。该方法在数据增强的背后应用了相同的思想,并通过在少数类的相邻实例之间插值来创建新的合成样本。
过度拟合
正如我们所知,我们的模型通过反向传播和最小化成本函数来学习/概括数据集中的关键特性。每一个来回的步骤都被称为一个轮次,并且随着每一个轮次的调整进行模型的训练和权值的更改,以最小化错误的代价。为了测试模型的准确性,一个常见的规则是将数据集分为训练集和验证集。
训练集用于调整和创建模型,让模型更加符合训练前的目的。验证集测试基于不可见样本模型的有效性。

在每一个轮次结束时,我们用验证集测试模型,在某个点上,模型开始记忆训练集中的特征。当我们到达某个阶段时,发现验证集上频繁的发生错误并且精度变差,这说明模型是过度拟合的。
选择网络的大小和复杂程度将是过度拟合的决定性原因。复杂的体系结构可能更容易过度拟合,但是,有一些策略可以防止过度拟合:
增加训练集上的样本数量;如果对网络进行更多实际案例的训练,它将具有更好的普遍性;
当过拟合发生时,停止反向传播是另一种选择,这样可以保证成本函数和验证集的准确性;
采用正则化的方法是另一个流行的选择。
L2正则化
L2正则化是一种通过向较大的个体权重进行分配约束来降低模型复杂度的方法。通过设置惩罚约束,减少模型对训练数据的依赖。
Dropout
对于正则化来说,Dropout也是一种常见的选择,它被用于较高层的隐藏单元上,然后我们为每个轮次建立了不同的架构。基本上,该系统随机选择要在训练中去除的神经元,通过不断地重新调整权重,网络被迫从数据中学习更普遍的模式。
结语
正如我们所看到的,有各种不同的方法和技术来解决图像识别中最常见的分类问题,每种方法和技术都有各自的优点和潜在的缺点。存在的一些问题是数据不平衡,过度拟合,其中最通常的问题是不会有足够的数据可用,但是,正如我们已经解释过的,它们可以通过迁移学习、抽样方法和正则化技术来解决。