PyTorch 在学术圈里已经成为最为流行的深度学习框架,如何在使用 PyTorch 时实现高效的并行化?
在芯片性能提升有限的今天,分布式训练成为了应对超大规模数据集和模型的主要方法。本文将向你介绍流行深度学习框架 PyTorch 最新版本( v1.5)的分布式数据并行包的设计、实现和评估。

Python API 前端
在设计 API 时,研究者制定了以下两个设计目标来达到必要的功能:
非侵入式:对应用提供的 API 必须是非侵入式的;
拦截式:API 需要允许拦截各种信号并立即触发适当的算法。
分布式数据并行化旨在使用更多的计算资源来加速训练。
根据以上需求,研究者用 nn.Module 实现了分布式数据并行。nn.Module 采用本地模型作为构造函数的参数,并在反向传播中透明地同步梯度。下面的代码是使用 DDP 模型的示例:

这些实验表明,不用等到每个梯度 tensor 都可用时再启动 AllReduce,DDP 在等待较短的时间并将多个梯度存储到一个 AllReduce 操作中时,就可以实现更高的吞吐量和更短的延迟。
通信重叠计算
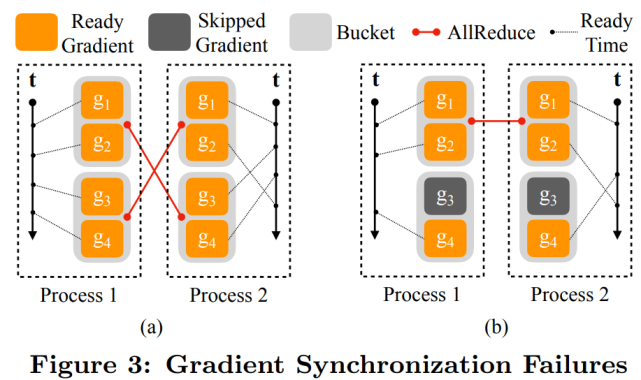
在使用分桶的情况下,DDP 只需在启动通信之前在同一个 bucket 中等待所有的内容。在这样的设置下,在反向传播的最后触发 AllReduce 就显得不足了。因此需要对更加频繁的信号做出相应,并且更加迅速地启动 AllReduce。因此,DDP 为每个梯度累加器都注册了 autograd 钩子。
下图 3(a)的示例中,两个竖直轴表示时间,虚线代表梯度准备就绪的时间。进程 1 中,4 个梯度按顺序计算。进程 2 中,g_2 在 g_3 和 g_4 之后计算;图 3(b)的示例中,梯度 g_3 对应的参数在一次迭代中被跳过了,导致 g_3 的就绪信号缺失。
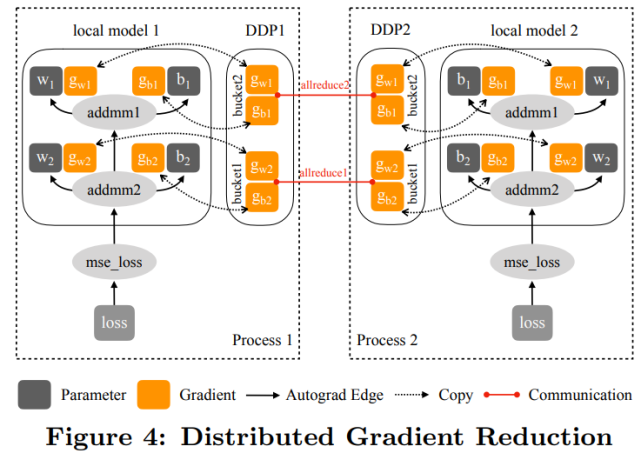
下图 4 展示了 DDP 在前向传播和反向传播过程中如何与本地模型交互:
聚合通信
DDP 是在集合通信库基础上建立的,包括 3 个选项 NCCL、Gloo 和 MPI。DDP 采用了来自这三个库的 API,并将它们封装进同一个 ProcessGroup API 中。
由于所有的通信都是聚合操作,因此所有的 ProcessGroup 实例上的后续操作必须和其类型匹配并遵循相同的顺序。对所有的库使用同一个 ProcessGroup API 允许研究者在相同的 DDP 实现上试验不同的通信算法。
如果单一 NCCL、Gloo 或 MPI 的 ProcessGroup 无法使链路容量达到饱和,通过使用循环的 ProcessGroups,DDP 可以获得更高的带宽利用率。
具体实现
DDP 的实现在之前的几个版本中已经改进了多次。研究者介绍了当前 PyTorch v1.5.0 的状态。DDP 同时在 Python 和 C++ 上都可以实现,Python 开放了 API 并组成了非性能关键因素组件,而 C++ 提供了核心梯度下降算法。Python API 通过 Pybind11 的 API 调用了 C++ 内核。
Python 前端
Python 前端中的实现细节决定了 DDP 的行为。可配置的 Knobs 在 DDP 构造函数 API 中开放。具体包括:
分组处理以找出 DDP 中运行 AllReduce 的进程组实例,它能够帮助避免与默认进程组混淆;
bucket_cap_mb 控制 AllReduce 的 bucket 大小,其中的应用应调整 knob 来优化训练速度;
找出没有用到的参数以验证 DDP 是否应该通过遍历 autograd 图来检测未用到的参数。
本地模型中的 Model Device Affinity 也能控制 DDP 的行为,尤其是当模型因为太大而需要跨越多个设备运行时,更是如此。对于大型模型,模型的每一层可以放在不同的设备上,使用 Tensor.to(device) API 可以将中间输出从一个设备转移到另一个上。DDP 也可以在多个模型上运行。
当层(例如 BatchNorm)需要跟踪状态,例如运行方差和均值时,模型缓冲器(buffer)是非常必要的。DDP 通过让 rank 为 0 的进程获得授权来支持模型缓冲器。
核心梯度下降
开发过程中的主要工作就是梯度降低,它也是 DDP 中决定性能的关键步骤。这个在 reducer.cpp 中的实现有 4 个主要的组成部分:构建 parameter-to-bucket map、安装 autograd 钩子,启动 bucket AllReduce 以及检测全局未用过的参数。
Parameter-to-Bucket Mapping 已经对 DDP 的速度有了相当大的影响。在每次反向传播中,tensor 从全部的参数梯度到 bucket 被复制,平均梯度在 AllReduce 之后又被复制回 tensor。
Autograd Hook 是 DDP 反向传播的进入点。在构造期间,DDP 遍历模型中的所有参数,找出每个参数的梯度累加器,并且为每个梯度累加器安装相同的 post-hook 函数。当相应的梯度准备就绪时,梯度累加器会启用 post hook,并且当整个 bucket 准备好启动 AllReduce 操作时,DDP 会确定启用。
Bucket Allreduce 是 DDP 中通信开销的主要来源。默认情况下,bucket 的大小是 25MB。
实验评估
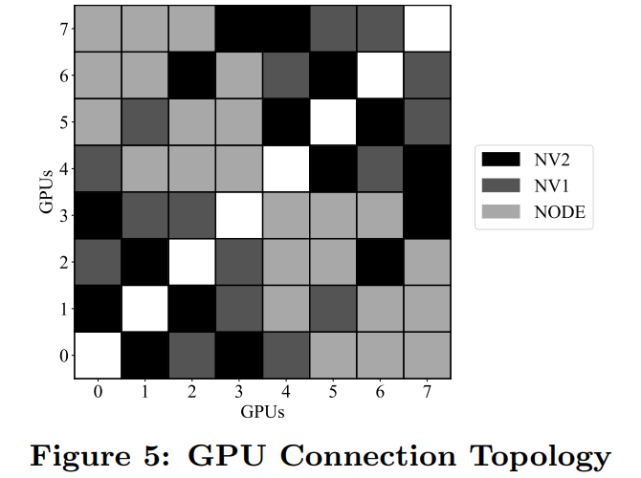
研究者展示了使用专属 32-GPU 集群和共享权限时 PyTorch DDP 的评估结果,其中 GPU 部署在 4 台服务器,并通过迈络思 MT27700 ConnectX-4 100GB/s 的网卡连接。每台服务器配有 8 个英伟达 Tesla V100 GPU。
下图 5 展示了一台服务器上 8 个 GPU 的互连方式:
结果显示,在 PyTorch DDP 训练时,反向传递是耗时最长的步骤,这是因为 AllReduce 通信(即是梯度同步)在这一过程中完成。
Bucket 大小
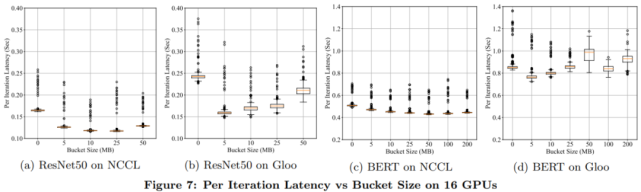
bucket 大小是一个重要的配置选项。根据经验,出于最大努力估计,bucket_cap_mb 的默认值是 25MB。研究者使用两台机器上的 16 个 GPU 比较不同 bucket 大小下每次迭代的延迟。另一个极端是在短时间内传递全部的梯度,结果如下图 7 所示。
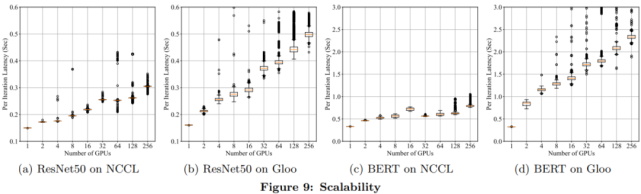
可扩展性
为了理解 DDP 的可扩展性,研究者用多达 256 个 GPU 上的 NCCL 和 Gloo 后端来度量 ResNet50 和 BERT 每次迭代的训练延迟。结果如下图 9 所示。
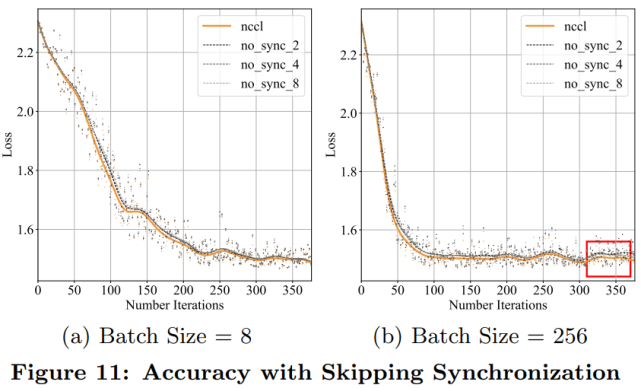
除了每次迭代延迟,测量收敛速度以验证加速度是否会因收敛放缓而被消除也非常关键。实验采用 MNIST 数据集来训练 ResNet。学习率设置为 0.02,批处理大小是 8。结果如下图 11(a)所示;图 11(b)是将批处理大小设为 256,学习率设为 0.06 的测量结果。
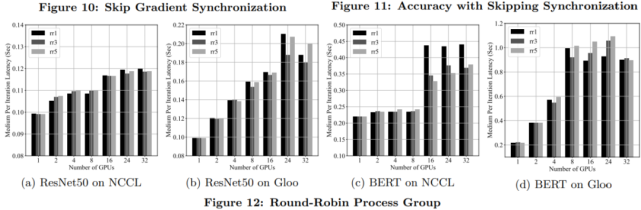
循环分配(Round-Robin)进程组
PyTorch 分布式包支持将 Round-Robin 进程组和多个 NCCL 或 Gloo 进程组组合在一起,从而按照 Robin-Robin 顺序向各个进程组实例分配聚合通信。
下图 12 展示了使用 1、3 和 5 个 NCCL 或 Gloo 进程组的 Round-Robin 进程组每次迭代的延迟。最显著的加速是使用 NCCL 后端的 BERT 模型。