相信大家在日常生活中,都见过类似下面的这些类似的字符串:
UTF-8
UTF-8可以使用1-4字节来表示字符,因为其兼容性强,可以对Unicode字符集中的所有有效编码点进行编码,是目前使用最广泛的编码标准。
与GB2312一样,UTF-8同样兼容ASCII编码。只是UTF-8比GB2312包含了更多字符,并且每种字符的字节数并不是完全固定的。由于编码规则比较复杂,这里不作具体解释,只会举例说明:
啊的实际数据为0xE5 0x95 0x8A
测的实际数据为0xE6 0xB5 0x8B
试的实际数据为0xE8 0xAF 0x95
其他编码
除了GB2312、UTF-8和ASCII编码,还有许多编码标准,他们大部分互不兼容。
存储和传输字符串数据
数据都是要进行存储和传输的
存储
微软使用BOM 头这种技术来为纯文本文件标记其编码,这样打开文件时就可以用正确的编码进行解析。
而大部分Linux不使用类似技术,所以读取后只能靠猜测,或强行指定,来进行显示。
传输
传输不仅指字符串数据在互联网上的传输,也包括了在各类函数调用过程中的传输。这类操作通常都不会带有字符编码标准的标记,一般靠直接指定编码来解决。
产生乱码
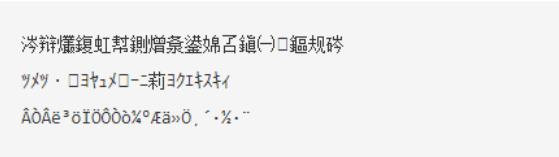
聪明的你应该已经想到了,如果一串某编码的数据,被人使用另一种编码标准进行解析,那么得出的结果几乎一定是错误的。
比如测试解析结果这几个字,我们使用UTF-8编码,得到下面16进制数据:

上面的过程就是典型的乱码形成过程
修复乱码
乱码是否可以还原?答案是肯定的,只需要按乱码形成时的操作反过来做一遍就可以恢复了。但是有些编码中会出现?这种无法解析显示的数据,这部分数据就完全丢失了。
一般的乱码修复操作,就是把各种编码可能性都试一遍,看哪个结果可靠,那么就是原始内容。
这里推荐使用开源的工具 llcom (llcom.papapoi.com),来进行乱码恢复工作
我们用上一节生成的乱码数据作为例子,尝试修复:

可以看到可靠的结果已经显示出来,修复成功
避免乱码
建议在写代码时统一使用UTF-8编码,这是目前互联网的最主要的编码形式
如果是资源占用紧张,但依旧需要中文显示的地方,可以考虑使用GB2312编码存储数据