在今天举办的Microsoft Ignite大会上,该公司推出了两款定制设计的芯片和集成系统:针对人工智能 (AI) 任务和生成式 AI 进行优化的 Microsoft Azure Maia AI 加速器,以及 Microsoft Azure Cobalt CPU——一款基于 Arm的处理器,专为在 Microsoft 云上运行通用计算工作负载而设计。
微软方面表示,这些芯片是微软提供基础设施系统的最后一块拼图,其中包括从芯片选择、软件和服务器到机架和冷却系统的一切,这些系统经过自上而下的设计,可以根据内部和客户工作负载进行优化。
Maia 100:5 nm工艺,1050 亿个晶体
据nextplatform引述微软CEO纳德拉的说法,微软的自研AI芯片Maia 100 芯片是基于台积电相同的 5 纳米工艺打造,总共包含 1050 亿个晶体管。这也因此,就晶体管或时钟速度而言,它并不轻量。而且,从公开数据开来,微软这颗芯片是迄今为止*的AI芯片。
散热方式上看,Maia 100 芯片采用直接液体冷却,一直运行 GPT 3.5,目前属于 GitHub 的 AI 副驾驶提供支持。微软正在使用 Maia 100 加速器构建机架,明年将被允许通过 Azure 云为外部工作负载提供支持。
具体性能方面,据semianalysis的报道,Maia 100在MXInt8下的性能为1600 TFLOPS,在MXFP4下则录得了 3200 TFLOPS的运算速度。semianalysis表示,虽然此处使用的数字格式是*的,但希望 MXInt8 是 FP16/BF16 的替代品,MXFP4 是 FP8 的替代品,至少对于推理来说是这样。这是非常简单的,但目前还算不错的启发式,因为没有人真正用这些数字格式训练过大规模模型。
从这些FLOPS 看来,该芯片完全彻底碾压了 Google 的 TPUv5 (Viperfish) 以及亚马逊的 Trainium/Inferentia2 芯片。与 Nvidia 的 H100 和 AMD 的 MI300X 相比,微软Maia 100的差距也并不远。
来到内存带宽方面,微软Maia 100的规格是 1.6TB/s 的内存带宽。这仍然碾压亚马逊的Trainium/Inferentia2,但却逊于TPUv5 ,更不用说 H100 和 MI300X 了。
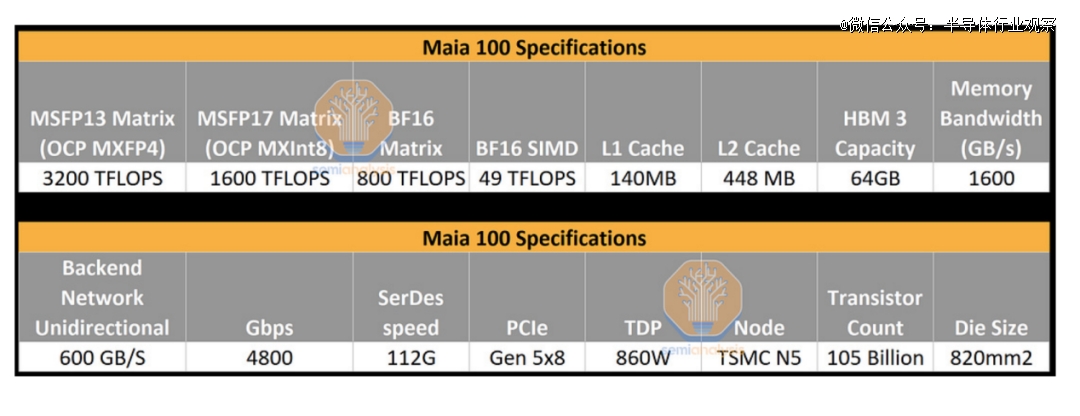
按照semianalysis的说法,之所以微软会出现这样的“错误”,是完全因为这该芯片是在LLM热潮发生之前设计的。因此,Maia 100在片上内存与片外内存方面有点不平衡——微软在芯片上放置了大量 SRAM,因为大量 SRAM 对于某些模型架构来说是有意义的。大型缓存通常有助于减少所需的内存带宽,但这不适用于大型语言模型。据介绍,微软在这个芯片上使用了 4 个 HBM 堆栈,而不是像 Nvidia 和AMD那样的 6 个和 8 个堆栈。
对于微软的这颗芯片,另一个亮点则在于其网络设计。如semianalysis所说, AMD 和 Nvidia 拥有 Infinity Fabric 和 NVLink,用于高速连接到少量附近的芯片(通常为 8 个),尽管 Nvidia 目前的一些部署数量已达到 256 个,但为了将数以万计的 GPU 连接在一起,Nvidia 和 AMD 需要将 PCIe 连接到以太网/InfiniBand 的网络附加卡。
但微软在这个芯片上采用了另外的一条道路——更类似于英特尔在其 Gaudi 系列加速器上所做的事情。那就是让每个芯片都有自己的内置 RDMA 以太网 IO。每个芯片 IO 总计为 4.8Tbps,这超过了 Nvidia 和 AMD,这与谷歌对其 TPUv5 和专有 ICI 网络所做的类似。
semianalysis表示,这个4.8T是单向的,是衡量联网速度的标准。当你在 NVLink 上计算 Nvidia 的数学时,实际上是 9.6T,而 H100/H200 是 7.2T。微软的 Maia 100 实际上比 Nvidia 拥有更多的扩展带宽,这是非常令人印象深刻的。
值得注意的是,Maia 100 还将 PCIe 通道减少至 8 个,以便*限度地扩大 112G SerDes 的区域。Nvidia 有 16 个通道,因为他们需要这些通道来连接到以太网/InfiniBand。Nvidia 还在其 C2C 上投入了区域,用于以高带宽将 Grace CPU 与 Hopper GPU 连接。如果我们包括短距离点对点互连,Nvidia 仍然*。
Cobalt 100:5nm工艺,128核N2
按照微软所说,Cobalt 100 CPU 是一款基于 Arm 架构(一种节能芯片设计)构建,并经过优化,可在云原生产品中提供更高的效率和性能的芯片。公司硬件产品开发副总裁 Wes McCullough 表示。选择 Arm 技术是 Microsoft 可持续发展目标的关键要素。它的目标是优化整个数据中心的“每瓦性能”,这本质上意味着消耗的每单位能源获得更多的计算能力。
虽然微软官方并没有披露该CPU的太多细节。但nextplatform引述传言表示, Cobalt 100是基于 Arm “Genesis”Neoverse Compute Subsystems N2 IP设计的。如果是这样的话,那么微软将采用两个 64 核 Generis 模块,其中每个模块带有“Perseus”N2 内核,每个内核有 6 个 DDR5 内存控制器,并将它们捆绑在一个插槽中。
换而言之,该芯片有 128 个核心和十几个内存控制器,这即使在2023 年也相当强大的。
“Perseus”N2 核心网格可在单个小芯片上从 24 个核心扩展到 64 个核心,其中四个可以组合在 CSS N2 封装中,以使用 UCI-Express(而非 CCIX)在插槽中扩展到最多 256 个核心或根据客户需求在小芯片之间进行专有互连。
Perseus 内核的时钟速度范围为 2.1 GHz 至 3.6 GHz,Arm 已优化了该内核、网格、I/O 和内存控制器的设计包,并采用台积电 (TSMC) 的 5 纳米工艺技术,从微软方面的消息看来, Cobalt 100 芯片也确实使用了这些制造工艺。微软表示,与 Azure 云中可用的以前的 Arm 服务器 CPU 相比,Cobalt N2 核心的每核心性能将提高 40%,纳德拉表示,微软的 Teams、Azure 通信服务和 Azure SQL 服务的部分已经在 Cobalt 100 上运行CPU。
Semianalysis则指出,Azure Cobalt 100 CPU 是微软在云中部署的第二款基于 Arm 的 CPU。他们署的*个基于 Arm 的 CPU 是从 AmpereComputing 购买的基于 Neoverse N1 的 CPU。Cobalt 100 CPU 就是在此基础上发展而来,并在 Armv9 上引入了 128 个 Neoverse N2 内核和 12 个 DDR5 通道。Neoverse N2 的性能比 Neoverse N1 高出 40%。
Cobalt 100 主要基于 Arm 的 Neoverse Genesis CSS(计算子系统)平台。Arm 的这一产品与仅授权 IP 的经典商业模式不同,使得开发基于 Arm 的优质 CPU 变得更快、更容易且成本更低。
自研芯片,蓄谋已久
在微软看来,芯片是云的主力。它们控制着数十亿个晶体管,处理流经数据中心的大量 1 和 0。这项工作最终允许您在屏幕上执行几乎所有操作,从发送电子邮件到用简单的句子在 Bing 中生成图像。
就像建造房屋可以让你控制每一个设计选择和细节一样,微软将添加自研芯片视为确保每个元素都是针对微软云和人工智能工作负载量身定制的一种方式。这些芯片将安装在定制服务器主板上,放置在定制的机架内,可以轻松安装到现有的微软数据中心内。硬件将与软件携手合作,共同设计以释放新的功能和机遇。
Azure 硬件系统和基础设施 (AHSI) 公司副总裁 Rani Borkar 表示,公司的最终目标是 让Azure 硬件系统能够提供*的灵活性,并且还可以针对功耗、性能、可持续性或成本进行优化。
“软件是我们的核心优势,但坦白说,我们是一家系统公司。在微软,我们正在共同设计和优化硬件和软件,以便一加一大于二,”Borkar说。“我们可以看到整个堆栈,而硅只是其中的成分之一。”
领导 Azure Maia 团队的微软技术研究员 Brian Harry 表示,Maia 100 AI 加速器是专为 Azure 硬件堆栈设计的。他表示,这种垂直整合——芯片设计与考虑到微软工作负载而设计的更大的人工智能基础设施的结合——可以在性能和效率方面带来巨大的收益。
AHSI 团队合作伙伴项目经理 Pat Stemen 则表示,2016 年之前,微软云的大部分层都是现成购买的。然后微软开始定制自己的服务器和机架,降低成本并为客户提供更一致的体验。随着时间的推移,硅成为主要的缺失部分。
在微软看来,构建自己的定制芯片的能力使微软能够瞄准某些品质并确保芯片在其最重要的工作负载上发挥*性能。其测试过程包括确定每个芯片在不同频率、温度和功率条件下的性能以获得*性能,更重要的是,在与现实世界的微软数据中心相同的条件和配置下测试每个芯片。微软强调,公司今天推出的芯片架构不仅可以提高冷却效率,还可以优化其当前数据中心资产的使用,并在现有占地面积内*限度地提高服务器容量。
为了更好地发挥两个芯片的实力,英特尔还在机架上花了很多功夫。
事实上,如nextplatform所说,长期以来,微软一直希望在其机群中找到 X86 架构的替代方案,早在 2017 年,微软就表示其目标是让 Arm 服务器占其服务器计算能力的 50%。几年前,微软凭借其“Vulcan”ThunderX2 Arm 服务器 CPU成为 Cavium/Marvell 的早期客户,当Marvell 在 2020 年底或2021年初做出封存 ThunderX3的决定时,微软有望成为“Triton”ThunderX3 后续 CPU的大买家。因此2022 年,微软采用了 AmpereComputing 的 Altra 系列 Arm CPU,并开始将其大量放入其服务器群中,但一直以来都有传言称该公司正在开发自己的 Arm 服务器 CPU,Cobalt 100 就成为了公司的答案。
正如nextplatform所说,此举对任何人来说都不会感到意外,因为即使微软没有部署太多自己的芯片,它们的存在本身就意味着它可以与芯片制造商英特尔、AMD 和 Nvidia 谈判以获得更好的定价。这就像花费数亿美元来节省数十亿美元,这些钱可以重新投资到基础设施上,包括进一步的开发。特别是考虑到 X86 服务器 CPU 的相对较高成本以及 Nvidia“Hopper”H100 和 H200 GPU 加速器以及即将推出的 AMD“Antares”Instinct MI300X 和 MI300A GPOU 加速器的惊人定价。由于供应有限且需求远远超过供应,AMD 根本没有动力在数据中心 GPU 的价格上低于 Nvidia,除非超大规模提供商和云构建商给他们提供一个。
这就是为什么每个超大规模提供商和云构建商目前都在致力于某种自研 CPU 和 AI 加速器的原因。正如我们喜欢提醒人们的那样,这就像 20 世纪 80 年代末和 90 年代 IBM 仍然垄断大型机时价值 100 万美元的 Amdahl coffee cup 一样。Gene Amdahl 是 IBM System/360 和 System/370 大型机的架构师,他创立了一家以他的名字命名的公司,生产克隆大型机硬件,并运行 IBM 的系统软件,当 IBM 销售代表来时,你的桌子上正好有那个杯子。通过这样来访传达了这样的信息:你不再胡闹了。
这是十年前亚马逊网络服务公司得出的结论是它需要进行自己的芯片设计的原因之一,但不是*的原因,因为最终(当然还没有发生)服务器主板,包括它的 CPU、内存、加速器和 I/O 最终将被压缩到片上系统。正如传奇工程师 James Hamilton 所说的那样,移动设备中发生的事情最终也会发生在服务器中。(我们会观察到,有时反之亦然。)有替代方案总是会带来竞争性价格压力。但更重要的是,通过拥有自己的计算引擎(Nitro、Graviton、Trainium 和 Inferentia),AWS 可以采用填充堆栈协同设计方法,最终共同优化其硬件和软件,提高性能,同时有望降低成本,从而推动性价比极限并注入营业收入现金。
微软在定制服务器、存储和数据中心方面起步较晚,但随着 Cobalt 和 Maia 计算引擎的加入,它正在成为 AWS 和 Google 以及 Super 8 中其他正在制造自己芯片的公司的快速追随者出于完全相同的原因。


