数据库的索引方式
由于许多查询只涉及文件中的少量记录,故我们需要能直接定位满足查询条件的功能。
索引的好处:
- 在查询中提高程序的性能。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 在使用分组和排序子句进行数据检索时,可以减少查询中分组和排序的时间。
索引的坏处:
- 创建索引和维护索引耗费资源和时间,且随数据量的增大而增大。
- 索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大。
- 在对表中的数据进行删除和修改时需要耗费较多的时间,因为索引也要动态的维护。
数据库中有两种基本的索引类型:
- 顺序索引:索引中的记录基于搜索码值顺序排序,包括索引顺序文件和 B+ 树索引文件等。
- 散列索引:索引中的记录基于搜索码值的散列函数的值平均地,随机地分布在若干个散列桶中。
顺序索引
1. 索引顺序文件
基本上克服了边长记录的顺序文件不能随机访问,以及不便于记录到的增加或删除。
记录仍然以关键字的顺序组织起来。引入了文件索引表,通过该表可以实现对索引顺序文件的随机访问。
在顺序文件组织的基础上,索引顺序文件分为两种:稠密索引和稀疏索引。
- 稠密索引:对应索引文件中搜索码的每一个值在索引中都有一个索引记录。每一个索引项包含搜索码值和指向既有该搜索码值的第一个数据记录(或文件块)的指针,因为在顺序文件组织基础上,所以知道第一个,下一个也会是相同的。
- 稀疏索引:只为文件中搜索码的某些值建立索引记录。每一个索引项包含搜索码值和指向具有该搜索码值的第一个数据记录的指针。
2. 多级索引文件
即使采用稀疏索引,对于一个大型数据库而言,索引本身也可能变得很大。
如果索引过大,主存中不能读入所有的索引块,这样的查询处理过程中,搜索索引就必须读大量的索引块。当然在索引上可以用二分法来定位索引块,但遗憾的是二分法不能处理有移除块的情况。
所谓多级索引就是在索引之上再建立稀疏索引,像对待其他顺序文件那样对待顺序索引。
3. 辅助索引
辅助索引是相对于聚集索引而言的,也叫非聚集索引。辅助索引的行存储的不是对应记录的全部信息,而是指向对应记录的指针。
所以,辅助索引必须是稠密索引,即对于每个搜索码值都必须有一个索引项,而且该索引项要存放指向数据文件中具有该搜索码值得所有记录的指针。
4. B+ 树索引
索引顺文件组织的最大不足在于:随着文件的增大,索引查找的性能和数据顺序扫描的性能会下降。虽然这种性能下降可以通过对文件进行重组来弥补,但频繁地进行重组也是要避免的。
B+ 树的特点:
- 根节点至少有两个子女。
- 每个中间节点有 [n/2] 到 n 个孩子节点,n 对特定的树是固定的。
- 采用平衡树结构,每个叶节点到根节点的路径长度相同。
- 每个节点中的元素从小到大排列,节点中 k-1 个搜索码值恰好是 k 个子节点域的划分。(即有 k-1 个值,k 个子节点)
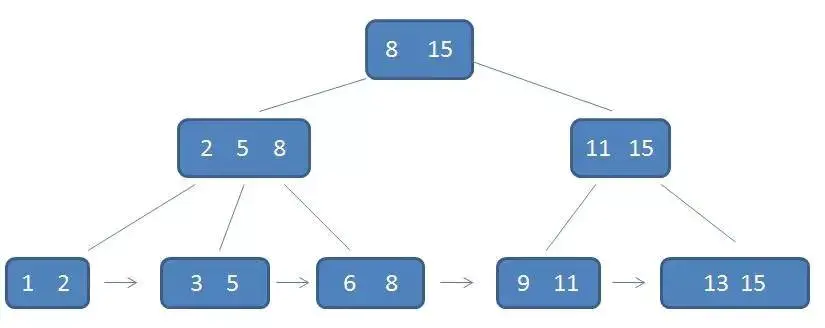
Mysql 不同搜索引擎的 B+ 树处理
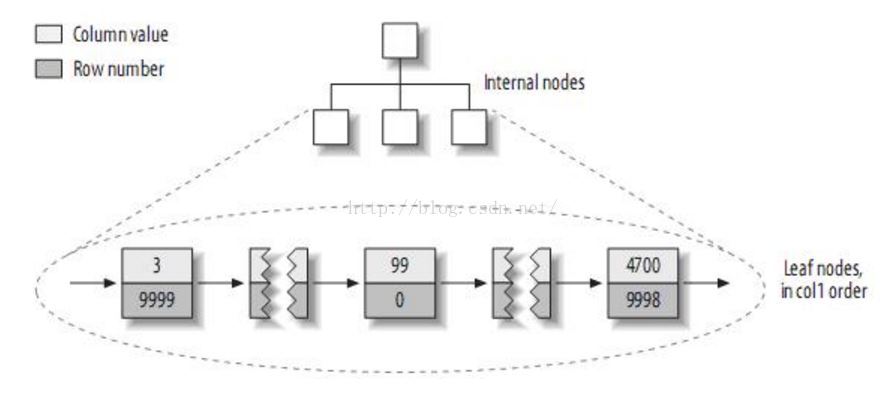
- MYISAM:按列值和行号来组织索引,它的叶子节点中保存的实践上是指向存放数据的物理课的指针。(即使用辅助索引)
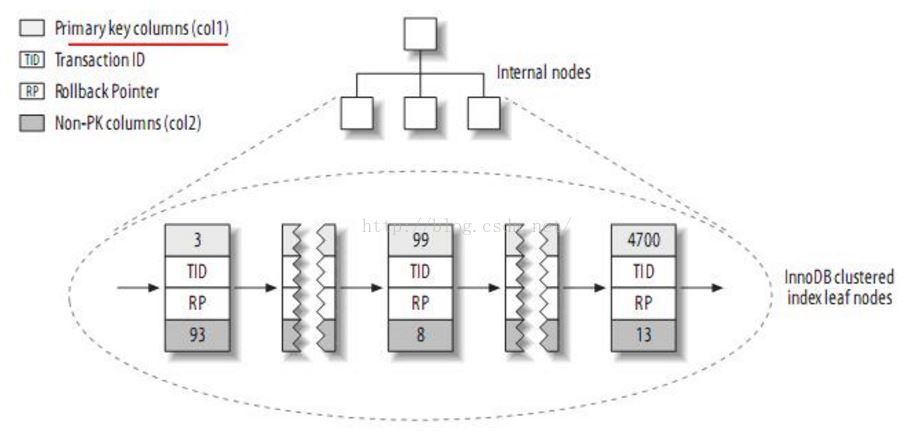
- InnoDB:按聚簇索引的形式存储数据,每个叶子节点除了包含整行记录,还包含事务 ID,回滚指针等。
聚簇索引:聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
优点:B+ 树的信息全部存放在叶子节点中,非叶子节点用来做索引,且叶子节点中有一个指针指向下一个叶子节点,这样做的目的是为了提高区间访问的性能。而正是这个特性决定了 B+ 树更适合用来存储外部数据。
散列索引
1. 散列文件组织
在散列的描述中,用散列桶来表示可以存放存储一条或多条记录的一个存储单位,通常一个桶就是一个磁盘块。通过散列函数计算搜索码值的散列值,并根据散列值来决定包含该搜索码值的记录该存储在哪个桶中。
散列文件的操作有:
- 查找:设带查找记录的搜索码值为 Ki,通过计算 h(Ki) 获取存储该记录的桶地址,然后到相应的桶中搜寻此记录,如果桶中没有找到,且存在溢出桶,还需要继续到溢出桶中寻找。
- 插入:插入一条搜索码值为 Ki 的记录,通过计算 h(Ki) 获得存储该记录的桶地址,然后就将该记录存入相应的桶(或溢出桶)中。
- 删除:待删除记录的搜索码值为 Ki,通过计算 h(Ki) 获得存储该记录的桶地址,然后到相应的桶(或溢出桶)中搜寻此记录并删除它。
溢出桶:如果一条记录必须插入桶 b 中,而桶 b 已满,系统会为桶 b 提供一个溢出桶,并将此记录插入到这溢出桶中。所有溢出桶用一个连接链表连接在一起,形成溢出链。
闭散列:溢出链的散列结构。
开散列:另一种接近溢出的方式,它的桶的数量是固定的,当一个桶满了,系统将记录插入到其他桶去,选择其他同的策略有:
- 使用下一个未满的桶,该策略称为线性探查法;
- 用进一步计算散列函数的方法。
2. 散列索引
散列索引将搜索码值及其相应的文件记录(或文件块)指针组织成一个散列索引项。散列索引的构建方法:
- 将散列函数作用于一条文件记录的搜索码值,以确定该文件记录所对应的散列索引项的散列桶。
- 将由该搜索码值以及相应文件记录(或文件块)指针组成的散列索引项存入散列桶(或溢出桶)中。
散列索引只能是一种辅助索引结构。
- 散列是非聚簇索引,故只能做辅助索引。
- 散列是稠密索引,如果其是聚簇索引的话,那么就成为了主索引了。
散列索引特点:散列其实就是一种不通过值的比较,而通过值的含义来确定存储位置的方法,他是为有效地实现等值查询而设计的。不幸的是,基于散列技术不支持范围检索,而基于 B+ 树的索引技术能有效地支持范围检索。但是,散列技术在等值连接等操作是很有用的,尤其是在索引嵌套循环连接方法中。
