神经网络简介
神经网络是深度学习系统的基石。为了在深度学习方面取得成功,我们需要从回顾神经网络的基础知识开始,包括架构、神经网络算法等等。
什么是神经网络?
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层
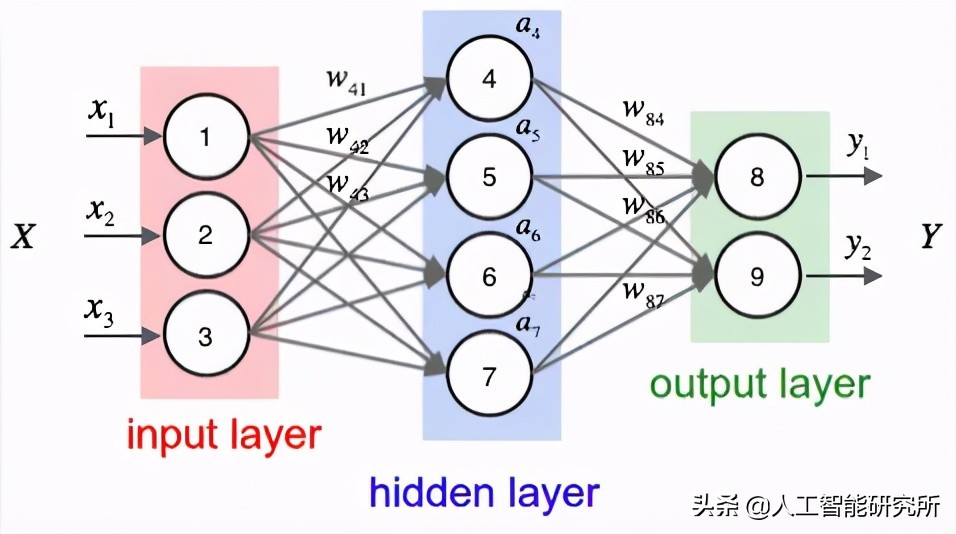

一个简单的神经网络架构。输入呈现给网络。每个连接通过网络中的两个隐藏层承载一个信号。最后一个函数计算输出类标签。
每个节点执行一个简单的计算。然后,每个连接将信号(即计算的输出)从一个节点传送到另一个节点,用权重标记,指示信号被放大或减弱的程度。一些连接具有放大信号的正权重,表明信号在进行分类时非常重要。其他的具有负权重,降低了信号的强度,从而指定节点的输出在最终分类中不太重要。我们称这样的系统为人工神经网络
人工模型
让我们首先看看一个基本的神经网络,它对输入执行简单的加权求和。值x 1 、x 2和 x 3是我们 NN的输入,通常对应于我们设计矩阵中的单行(即数据点)。常数值 1 是我们的偏差,假定已嵌入到设计矩阵中。我们可以将这些输入视为神经网络的输入特征向量。

从上面的等式我们可以看出,这是一个非常简单的阈值函数。如果加权和 ∑ n i =1 w i x i > 0,则输出 1,否则输出 0。
沿x轴输入值,沿y轴绘制f ( net )的输出,我们可以看到为什么这个激活函数由此得名。当net小于或等于零时,f的输出始终为零。如果net大于零,则f将返回 1。
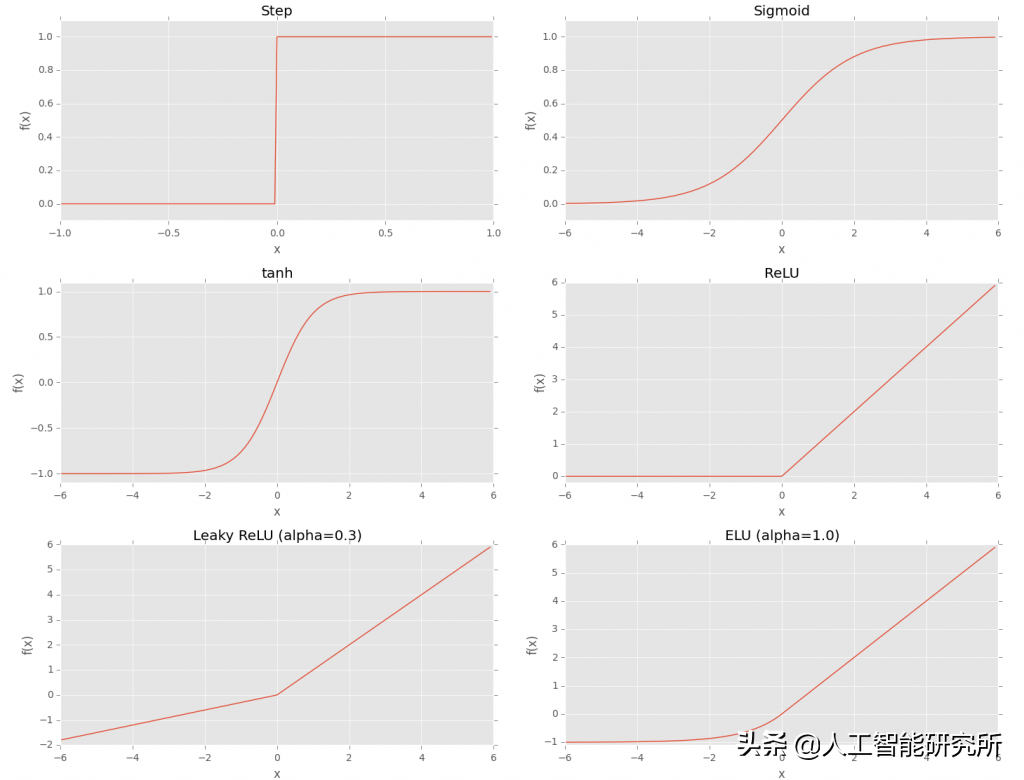
sigmoid 函数是比简单阶跃函数更好的学习选择,因为它:
- 处处连续且可微。
- 围绕y轴对称。
- 渐近地接近其饱和值。
这里的主要优点是 sigmoid 函数的平滑性使得设计学习算法变得更加容易。但是,sigmoid函数有两个大问题:
- sigmoid 的输出不是以零为中心的。
- 饱和神经元基本上会杀死梯度,因为梯度的增量非常小。
直到 1990 年代后期,双曲正切或tanh(具有类似 sigmoid 的形状)也被大量用作激活函数:tanh的方程如下:
f ( z ) = tanh ( z ) = ( e z -e -z ) / ( e z + e -z )
所述的tanh函数零为中心,但是,当神经元变得饱和梯度仍然杀死。
我们现在知道激活函数有比 sigmoid 和tanh函数更好的选择。
f ( x ) = max (0 , x )
ReLU 也被称为“斜坡函数”,因为它们在绘制时的外观。注意函数对于负输入是如何为零的,但对于正值则线性增加。ReLU 函数是不可饱和的,并且在计算上也非常高效。
根据经验,在RELU激活功能趋于超越sigmoid 和tanh在几乎所有的应用功能。ReLU 激活函数比之前的激活函数家族具有更强的生物动机,包括更完整的数学理由。
截至 2015 年,ReLU 是深度学习中最流行的激活函数。然而,当我们的值为零时会出现一个问题——不能采用梯度。
ReLU 的一种变体,称为Leaky ReLU允许在单元不活动时使用小的非零梯度:
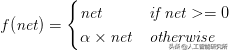
α的值是常数,并在网络架构实例化时设置——这与学习效率α 的PReLU 不同。对于一个典型的值α是α = 1 。ELU 通常比 ReLU 获得更高的分类准确率。

具有 3 个输入节点、具有 2 个节点的隐藏层、具有 3 个节点的第二个隐藏层以及具有 2 个节点的最终输出层的前馈神经网络示例。
使用哪个激活函数?
鉴于最近深度学习的普及,激活函数出现了相关的爆炸式增长。由于激活函数的选择数量众多,现代(ReLU、Leaky ReLU、ELU 等)和“经典”(step、sigmoid、tanh等),它可能看起来令人生畏,如何来选择合适的激活函数。
然而,在几乎所有情况下,建议从 ReLU 开始以获得基线准确度。从那里可以尝试将标准 ReLU 换成 Leaky ReLU 变体。
前馈网络架构
虽然有许多神经网络的前馈架构,最常见的结构是Feedforward网络
在这种类型的架构中,节点之间的连接只允许从第i层的节点到第i +1层的节点。不允许向后或层间接连接。当前馈网络包括反馈连接(反馈到输入的输出连接)时,它们被称为循环神经网络。
我们专注于前馈神经网络,因为它们是应用于计算机视觉的现代深度学习的基石。卷积神经网络只是前馈神经网络的一个特例。
为了描述一个前馈网络,我们通常使用一个整数序列来快速简洁地表示每一层的节点数。例如,上图中的网络是一个3-2-3-2前馈网络:
第 0 层包含 3 个输入,即我们的x i 值。这些可能是图像的原始像素强度或从图像中提取的特征向量。
第 1 层和第 2层分别是包含 2 个和 3 个节点的隐藏层。
第 3 层是输出层或可见层——在那里我们可以从网络中获得整体输出分类。输出层通常具有与类标签一样多的节点;每个潜在输出一个节点。例如,如果我们要构建一个神经网络来对手写数字进行分类,我们的输出层将包含 10 个节点,每个节点代表0-9。
神经网络有什么用?
当然,如果使用适当的架构,神经网络可用于监督、无监督和半监督学习任务。神经网络的常见应用包括分类、回归、聚类、矢量量化、模式关联和函数逼近等等
事实上,对于机器学习的几乎每个方面,神经网络都以某种形式得到应用。
1、无人驾驶汽车
无人驾驶使用到了很多人工智能方面的技术,其中一个计算机视觉便是使用CNN卷积神经网络让无人驾驶能够看到路面路况等
2、人脸识别
人脸识别的应用就比较广泛了,手机人脸解锁,人脸付款,人脸打卡等
3、机器翻译
随着人工智能学习能力的不断提升,机器翻译的准确性得到了大幅提高
4、声纹识别
生物特征识别技术包括很多种,除了人脸识别,目前用得比较多的还有声纹识别。声纹识别是一种生物鉴权技术,也称为说话人识别,包括说话人辨认和说话人确认。
声纹识别的工作过程为,系统采集说话人的声纹信息并将其录入 数据库 ,当说话人再次说话时,系统会采集这段声纹信息并自动与数据库中已有的声纹信息做对比,从而识别出说话人的身份。声纹解锁APP,控制智能家居等等
5、AI智能机器人
机器人的发展经历了漫长的发展,随着人工智能技术的发展,给机器人加上了智能的翅膀
6、智能家居
智能音箱,智能冰箱,洗衣机,空调,电视等等,随着人工智能技术的发展,现在的家庭家居貌似没有点人工智能的点缀,便不好意思立足家居行业
7、推荐系统
大量的数据喂给人工智能,给人带来了更多的便利推荐,个性化推荐系统广泛存在于各类网站和App中,本质上,它会根据用户的浏览信息、用户基本信息和对物品或内容的偏好程度等多因素进行考量,依托推荐引擎算法进行指标分类,将与用户目标因素一致的信息内容进行聚类,经过协同过滤算法,实现精确的个性化推荐。
8、图像搜索
大量浏览器中的相似图片搜索,该技术的应用与发展,不仅是为了满足当下用户利用图像匹配搜索以顺利查找到相同或相似目标物的需求,更是为了通过分析用户的需求与行为,如搜索同款、相似物比对等
9、大健康
未来医疗,大健康行业会越来越多地走入人类的生活,未来随着智能AI的加入,相信人类会提前预测自己的疾病,给人类带来更加美好的明天。
以上等等都会使用到人工智能的神经网络技术,就像人类一样,未来的机器会越来越多的有自己的神经网络,也会越来越聪明。