如果把时钟拨到2023年底,当我们回过头来看今年科技界最激动人心的大事件,ChatGPT的横空出世无疑会占据一席之地。就像几年前大家被谷歌AlphaGo点燃对人工智能的热情一样,人们对ChatGPT的热情只多不少。
并且,AlphaGo其实只是虚晃一枪,并没能带来很多的实际应用,而ChatGPT不一样,商业应用速度异常迅速,超过了大部分的预期。OpenAI很快推出了GPT-4,微软很快将相应模型接入其搜索、office全家桶等各条业务线;谷歌以Bard仓促应战,并与其搜索业务深度绑定,褒贬不一;国内的百度以文心一言快速跟进,目前已经有数十万家企业在排队接入文心一言;阿里巴巴发布的通义千问,同样得到数十万企业的热情回应。
人们对于这类AI应用的热情可见一斑。
实际上,人工智能、可控核聚变、元宇宙这三个领域的每一次突破,都将极大的挑动人类敏感的神经,都能引发一波全民追捧热浪。
然而,外行看热闹,内行看门道。作为一个专业媒体,数据猿并不满足于报道浮在行业表面的热点新闻,而要试图去挖掘隐藏在冰山底下的秘密。
在我们看来,虽然现在ChatGPT已经成为万众瞩目的明星,但它却只是摆在台面上的“提线木偶”,真正隐藏在幕后操控这一切的幕后大佬另有其人。
一言以蔽之:ChatGPT只是表面的喧嚣,大模型才是刺破AI的那柄尖刀。
所以,要搞清楚目前的状况,应该把更多的注意力放在底层的大模型上,而不是停留在ChatGPT上。正如上一轮AlphaGo引发的AI浪潮,其底层驱动力是深度学习技术的突破。
接下来,我们就来深入分析一下大模型,试图搞清楚大模型跟以往的机器学习、深度学习模型有什么不一样;大模型这么厉害,那它到底是如何工作的。
1、大模型是深度学习技术的进化版
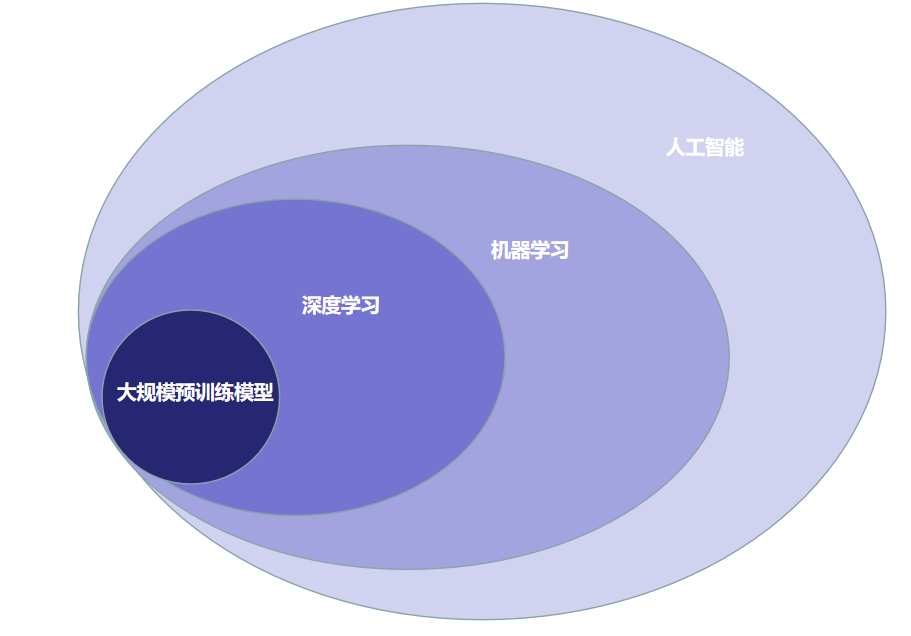
人工智能已经发展了几十年了,整体朝着机器学习、深度学习、大模型的进化方向发展。
人工智能是一种广义的概念,指的是使机器能够表现出人类智能的任何技术。机器学习是实现人工智能的一种方法,它通过让机器从数据中学习,自动发现数据中的模式和规律。深度学习是机器学习的一种特殊形式,它使用深度神经网络进行学习和预测。
大规模预训练模型是一种机器学习模型,使用大量数据进行预训练,并在后续任务中进行微调。这种模型通常采用深度学习技术,可以自动从数据中提取特征和模式,从而进行各种任务,例如自然语言处理、图像识别、语音识别等。目前最著名的大规模预训练模型之一是 GPT系列。
大规模预训练模型可以被看作是深度学习技术的一种进化和扩展,大规模预训练模型通常也使用了以往深度学习模型的一些技术,如卷积神经网络、循环神经网络等。通过预训练加微调的方式,大规模预训练模型在处理大规模数据和多个任务方面具有很强的能力,成为了当前人工智能领域的一个重要研究方向。
因此,大模型、深度学习、机器学习、人工智能的关系可以用下图来表示:
 数据猿制图
数据猿制图
深度学习技术可以视为大模型的地基之一,大模型发展也跟深度学习技术的突破息息相关。2012-2018年,深度学习技术在默默发展,2018年OpenAI推出GPT模型为分水岭,大模型的发展进入加速阶段。各个科技巨头都开始狂炼大模型,一方面是在核心算法上进行探索,另一方面就是的不断提升参数规模——大模型领域的“暴力美学”。
当然,除了美国,中国在大模型领域是跟的最紧的,百度、腾讯、阿里巴巴、华为等也诞生了不少成果。
其中,百度在这个领域的积累最深,这也是百度能在中国率先推出对标ChatGPT的文心一言产品的原因。
接下来我们试图从技术角度,来探讨一下大模型产业发展的核心逻辑。
2、全新的训练模式:预训练+微调
同样是深度学习技术,为什么大模型能表现的如此惊艳,它有什么不一样呢?
以往的深度学习模型通常需要从头开始训练,需要大量的标注数据和计算资源。而大规模预训练模型则采用了一种更加高效的训练方式,即预训练加微调。预训练是指在海量数据上进行无监督学习,使得模型学到更加通用的特征和表示。在预训练完成后,可以在不同的任务上进行微调,使得模型能够适应具体的任务。
可以发现,大模型的训练有两个关键的步骤,即预训练+微调。通过预训练,来获得一些通用特征,并提升模型泛化能力。
在大规模预训练模型中,通用的特征和表示指的是一些基本的语言或图像特征,这些特征是在模型在大规模数据上无监督学习时自动学习到的。
这些通用的特征和表示具有一定的抽象性,可以在不同的任务中被重新利用,从而使得模型可以更加高效地学习新的任务。这就像是学生在学习不同的科目时,会学到一些基本的学习方法和技巧,比如如何理解概念、如何思考问题、如何进行逻辑推理等等。这些基本的学习方法和技巧可以被应用在不同的科目中,帮助学生更加高效地学习和掌握知识。
目前大模型的泛化效果已经相当不错,比如在自然语言处理领域,大模型如GPT-4在多个NLP任务上均取得了出色的表现,表明大模型在泛化方面已经取得了很大的进展。未来的突破重点可能在于进一步提高模型的泛化能力,比如在数据增强、对抗训练等方面继续探索创新方法。
相比之前的深度学习模型,大模型之所以能够实现更好的泛化能力,关键在于大模型具有更多的参数和更丰富的特征表示能力。大模型在预训练阶段就能够学习到大规模数据的特征表示,这些通用的特征能够被迁移应用到各种不同的任务中,使得大模型能够更好地适应新的任务,从而提高了泛化能力。
关于泛化能力,可以把它比喻成一个人的适应能力。如果一个人只是在自己家里待着,很少接触外面的世界,那么他可能很难适应到新的环境中去。但是如果一个人经常外出旅行,接触不同的文化和环境,那么他的适应能力就会更强,无论面对何种情况,都能够迅速适应。同样地,一个模型的泛化能力越强,也就意味着它对于不同的数据集都能够有很好的适应能力。
举个例子,假设你是一个学习者,正在学习如何区分不同种类的水果。传统的深度学习模型可能只能学习到一些基础的特征,比如颜色、大小等,但是如果遇到一些特殊的水果,比如火龙果、杨桃等,模型可能就无法正确识别。这就好比你只是学习了苹果、香蕉等常见水果的特征,但对于火龙果、杨桃这类非常规的水果,你可能无从下手。但是,如果你使用了一种大规模预训练模型,就好比你已经学习了各种不同种类的水果的特征,并且可以将这些特征迁移到新的水果上。这样,即使你遇到了一些之前没见过的水果,也可以根据它们的特征正确地识别它们。
3、自监督学习,数据“爆炸”的引信
从上面的分析可以发现,足够多的数据,是大模型实现泛化的重要基础,只有模型“见多识广”了,遇到以前没见过的情况才可以从容应对。
事实上,大模型之所以能取得如此惊艳的表现,有一个关键的突破,就是训练数据集的扩大。
数据猿对比了机器学习模型(以随机森林模型为例)、传统深度学习模型和大模型的训练数据集规模。发现大模型的训练数据集规模要比传统深度学习高几个数量级,至于更传统的机器学习模型就更没有可比性了。
既然训练数据集规模越大模型的表现越好,那为什么以前不把数据集规模做大呢?不是不想,是不能。传统深度学习模型的训练数据,大多是标注数据,对数据进行标注是一个费时费力的过程,这极大的限制了数据规模。
要打破数据标注的桎梏,自监督学习技术闪亮登场了。
自监督学习是一种无需人工标注数据的机器学习方法,它通过利用数据自身的内在结构,训练模型来学习数据的特征表示。其核心思想是在未标注数据上构建模型,并从数据中自动发现模式和结构。自监督学习已经在计算机视觉、自然语言处理、语音识别等领域中得到广泛应用。
自监督学习的核心技术包括预测任务的设计、数据增强方法和模型架构的设计:预测任务的设计是指在未标注的数据上构建一些任务,让模型通过这些任务来学习数据的特征表示。数据增强方法则是通过对未标注数据进行一些变换和扰动,生成新的数据来扩充训练集,提高模型的泛化能力。模型架构的设计则是指选择合适的网络结构和优化算法,使得模型能够从未标注数据中学习出有用的特征表示。
具体来看,实现自监督学习的具体过程包括以下几个步骤:
收集未标注数据集。未标注数据集的选择和收集对于自监督学习的效果至关重要,需要根据具体任务选择适合的数据集。
设计预测任务。预测任务的设计需要根据具体任务选择合适的目标和方法,如图像分类、图像重构、图像补全等。
数据增强。数据增强可以提高模型的泛化能力,可以通过图像旋转、裁剪、变形等方法来扩充数据集。
构建模型。模型的选择和设计需要根据具体任务选择适合的模型架构和优化算法。
模型训练。使用未标注数据进行模型训练,通过优化损失函数来学习数据的特征表示。
模型评估。对训练好的模型进行评估,包括特征表示的质量、模型的泛化能力和任务性能等指标。
需要指出的是,自监督学习技术已经有超过20年的发展历史。
冰冻三尺非一日之寒,虽然看起来ChatGPT是突然爆火的,但其核心的大模型技术却是经过了多年的发展,一点点突破之后。从深度学习到大模型,从标注数据训练到基于自监督学习的非标注数据训练,技术的发展就像一场接力赛,然后在最近达到了一个临界点。
4、十年大模型无人问,一朝ChatGPT天下知
我们不仅要看到表面的热闹,也要看到产业背后的发展脉络和逻辑。只有掌握产业的底层密码,才能真正融入时代的浪潮,而不只是当一个吃瓜群众。
ChatGPT爆火之后,中国有大量的公司想要搭上这趟快车,纷纷高调宣布自己已经或者即将推出对标的产品。
当我们关注ChatGPT时,视角应该放在GPT,而不是Chat!
中国公司能否推出对标ChatGPT的产品,核心也在于底层大模型的突破,而不是推出一个跟ChatGPT“长得像”的对话式AI产品。